
Scraping de medios: clipping con código
Parte de mi rutina cotidiana involucra hacer un recorrido por distintos medios para ponerme al día de todos los últimos acontecimientos. Pero como hay tanto por leer y por hacer, decidí hacerme la tarea un poco más amena, y de paso, sentar las bases para futuras y mejores investigaciones sobre el rol de los medios y la generación de un sentido común.
Muchos de los medios nacionales e internacionales cuentan en su haber con el protocolo RSS, que permite tener un acceso estandarizado a cierto tipo de contenido online: de este modo, con una app o un agregador, potencialmente se puede acceder a todo el contenido de un simple vistazo. Por eso decidí construirme una serie de funciones que hoy voy a compartir con ustedes para acceder a toda esta información y poder procesarla luego.
En los hombros de los gigantes
Para esta tarea, me crucé con un paquete increíblemente sencillo llamado tidyRSS, cuya función es levantar los RSS en un formato listo para trabajar.
Quiero hacer una pequeña digresión antes de pasar al código y gráficos. Una de las cosas que me parecen maravillosas de la comunidad de R es la predisposición de todxs lxs involucradxs a compartir el conocimiento (es en parte lo que me motivó a hacer este blog) y a ayudar al prójimo, siempre que esté al alcance de las posibilidades.
Menciono esto porque me encontré con un error 403 intentando levantar Página/12, que quiere decir que no tengo permisos para acceder. Al ser un diario, supuse que no debería suceder, con lo que le escribí al autor del paquete, el investigador Robert Myles McDonnell. Me respondió a las escasas horas y se puso él mismo manos a la obra para intentar resolver el problema, pero no hubo caso. No habré podido solucionar ese problema, pero por lo menos me quedé tranquilo de que si ni el mismo creador del paquete podía acceder, al menos lo había intentado todo. Así que quiero dejar un gran agradecimiento para él, y una recomendación a todos los colegas a que se pasen por su sitio web (https://robertmyles.github.io/) a revisar su trabajo.
Ahora sí, ¡a trabajar!
Manos a la obra
Vamos a cargar tidyverse, la ya mencionada tidyRSS y los dos paquetes de referencia para análisis de palabras: tm y tidytext.
library(tidyverse)## -- Attaching packages ------------------------------------------------- tidyverse 1.2.1 --## v ggplot2 3.0.0 v purrr 0.2.5
## v tibble 1.4.2 v dplyr 0.7.6
## v tidyr 0.8.1 v stringr 1.3.1
## v readr 1.1.1 v forcats 0.3.0## -- Conflicts ---------------------------------------------------- tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(tidyRSS)
library(tidytext)
library(tm)## Loading required package: NLP##
## Attaching package: 'NLP'## The following object is masked from 'package:ggplot2':
##
## annotateEn esta oportunidad voy a trabajar con La Nación, a modo de ejemplo. La realidad es que el procedimiento es esencialmente el mismo para cualquier diario, así que mirando cómo armé este pueden hacerlo con cualquier otro medio.
Revisando los medios (o directamente googleando el nombre y RSS) van a poder encontrar dónde se alojan los RSS y cómo son los links en cada canal. En el caso de La Nación, todo está en https://servicios.lanacion.com.ar/herramientas/rss/ayuda.
Lo que me propuse hacer es construir una tabla con una serie de datos: título, bajada, url, entre otros. De ahí, usando el lexicón SDAL que ya había utilizado en mi post del análisis de #miracomonosponemos (https://hernanescu.github.io/2018/12/mira-como-nos-ponemos/), separar cada noticia por palabra y cruzarlo con el lexicón, para así obtener una medida muy estimativa de si es positiva o negativa. Con el diario del lunes (y después de unas cuantas horas de codeo), considero que es aún bastante impreciso como calificación de la noticia, pero decidí dejarlo de todos modos. Es un tema que me interesa y en el que quiero seguir trabajando.
La función es un tanto larga, pero la voy a ir detallando para que sea claro y quienes quieran puedan replicar con otros casos (y modificar a su gusto). Veamos entonces de qué se trata:
scrap_ln <- function(){
#1. Cargo el lexicón adentro de la función para hacer el cruce
sdal <- read.csv('https://hernanescu.github.io/data/SDAL.csv')
#2. Levanto los feeds, agregándole a cada uno la columna "section" con su origen
ln_ultimas <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/origen=2') %>%
mutate(section="Últimas Noticias")
ln_politica <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=30') %>%
mutate(section="Política")
ln_economia <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=272') %>%
mutate(section="Economía")
ln_deportes <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=131') %>%
mutate(section="Deportes")
ln_sociedad <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=7772') %>%
mutate(section="Sociedad")
ln_opinion <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=28') %>%
mutate(section="Opinión")
ln_espectaculos <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=120') %>%
mutate(section="Espectáculos")
ln_mundo <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=7') %>%
mutate(section="El Mundo")
ln_revista <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=494') %>%
mutate(section="Revista La Nación")
ln_comex <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=347') %>%
mutate(section="Suplemento Comercio Exterior")
ln_tech <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=432') %>%
mutate(section="Suplemento Tecnología")
ln_campo <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=337') %>%
mutate(section="Suplemento El Campo")
ln_moda <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=1312') %>%
mutate(section="Suplemento Moda y Belleza")
ln_comunidad <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=1344') %>%
mutate(section="Suplemento Comunidad")
ln_adn <- tidyfeed('http://contenidos.lanacion.com.ar/herramientas/rss/categoria_id=6734') %>%
mutate(section="adnCultura")
#3. Armo una base que contiene todo el diario
ln_full <- rbind(ln_ultimas, ln_politica, ln_economia, ln_deportes,
ln_sociedad, ln_opinion, ln_espectaculos, ln_mundo, ln_revista,
ln_comex, ln_tech, ln_campo, ln_moda, ln_comunidad, ln_adn)
#4. Agrego una columna vacía donde luego va a ir el puntaje de cada noticia
ln_full$score <- 0
#5. Loop que deshace cada noticia en palabras y las puntúa
for (i in 1:nrow(ln_full)) {
news.i <- ln_full[i,]
word_news.i <- news.i %>%
select(item_title, item_content) %>%
gather(col_orig, texto, 1:2)%>%
unnest_tokens(input=texto, output=palabra) %>%
count(palabra) %>%
filter(!palabra%in%stopwords('es')) %>%
left_join(., sdal, by="palabra") %>%
filter(!is.na(media_agrado)) %>%
mutate(score=n*media_agrado)
mean.i <- sum(word_news.i$score)/sum(word_news.i$n)
ln_full$score[i] <- mean.i
}
#6. Evaluación de cada noticia según su puntaje y wrangling general
ln_full <- ln_full %>%
mutate(rating=case_when(score>1 & score<=1.75 ~ "Negativa",
score>1.75 & score<=2.25 ~ "Neutral",
score>2.25 & score <=3 ~"Positiva")) %>%
rename("title"=item_title,
"description"=item_content,
"URL"=item_link,
"fecha"=item_date_updated) %>%
mutate(site="La Nación") %>%
select(site, section, title, description, score, rating, fecha, URL)
#7. Asignar el resultado para poder trabajarlo
assign("la_nacion", value=ln_full, pos =1)
}¡Ya tenemos nuestra función! Veamos de qué se trata:
scrap_ln()
head(la_nacion)## # A tibble: 6 x 8
## site section title description score rating fecha URL
## <chr> <chr> <chr> <chr> <dbl> <chr> <dttm> <chr>
## 1 La Na~ Últimas~ Arge~ La Argenti~ 2.48 Posit~ 2019-01-22 11:03:00 http~
## 2 La Na~ Últimas~ Cómo~ El avión q~ 2.21 Neutr~ 2019-01-22 10:58:00 http~
## 3 La Na~ Últimas~ Quié~ Emiliano S~ 2.31 Posit~ 2019-01-22 10:27:00 http~
## 4 La Na~ Últimas~ Desa~ NANTES.- E~ 2.27 Posit~ 2019-01-22 09:46:00 http~
## 5 La Na~ Últimas~ La A~ La Adminis~ 2.07 Neutr~ 2019-01-22 07:11:00 http~
## 6 La Na~ Últimas~ Cuál~ ¿Cuánto ga~ 2.17 Neutr~ 2019-01-22 05:54:00 http~Podemos ver que tenemos todo lo necesario para arrancar la mañana informado (al menos superficialmente) y sin tener que abrir la página en sí. Nada mal, pero, ¿qué más podemos hacer con esto?
En el diario no hablaban de tí
Tenemos esta data pre-procesada y sería una pena desperdiciarla. Así que juguemos un poco más: veamos una función para desarmar todo en palabras y así poder contar los términos más usados (y comparar con otros medios). scrap_word, como la bauticé en un rapto de creatividad, toma dos argumentos: la base de datos del medio y la sección que querramos analizar.
Un par de aclaraciones importantes: el primer argumento, por cómo está construida la función, toma la base pre-procesada respetando los nombres que yo le puse, con lo que si deciden cambiarle algo tengan cuidado y reemplacen todo lo que haga falta. En ese mismo sentido, el argumento que toma la sección tiene que respetar los nombres que yo asigné anteriormente. Si ese segundo argumento no se especifica, la función toma toda la base de datos, lo cual es ideal para hacer una lectura general, así como también procesar medios que no tengan secciones especificadas en su RSS (Infobae, te miro a vos).
scrap_word <- function(media, section_m){
if(missing(section_m)) {
media_name <- media$site[1] #extraemos el nombre del sitio
section_name <- "Sitio" #esta es la parte que no especifica sección
media_words <- media %>%
gather(., key=noticias, value=palabras, 3:4) %>%
unnest_tokens(input = palabras, output=word) %>%
count(word) %>%
arrange(desc(n)) %>%
filter(!word%in%stopwords('es'))
media_words$site <- media_name
media_words$section <- section_name
db_name <- paste0(media_name, sep="_", section_name)
assign(x=db_name, value = media_words, pos=1)
}
else {
media_name <- media$site[1] #extraer nombre del medio
section_name <- deparse(substitute(section_m)) #extraer sección del medio
media_words <- media %>%
gather(., key=noticias, value=palabras, 3:4) %>%
filter(section==section_name) %>%
unnest_tokens(input = palabras, output=word) %>%
count(word) %>%
arrange(desc(n)) %>%
filter(!word%in%stopwords('es'))
media_words$site <- media_name
media_words$section <- section_name
db_name <- paste0(media_name, sep="_", section_name)
assign(x=db_name, value = media_words, pos=1)
}
}Veamos primero cómo funciona sin especificar una sección:
scrap_word(la_nacion)
head(`La Nación_Sitio`)## # A tibble: 6 x 4
## word n site section
## <chr> <int> <chr> <chr>
## 1 años 37 La Nación Sitio
## 2 cómo 27 La Nación Sitio
## 3 argentina 26 La Nación Sitio
## 4 dos 25 La Nación Sitio
## 5 gobierno 25 La Nación Sitio
## 6 mundo 23 La Nación SitioY al especificar:
scrap_word(la_nacion, Política)
head(`La Nación_Política`)## # A tibble: 6 x 4
## word n site section
## <chr> <int> <chr> <chr>
## 1 macri 17 La Nación Política
## 2 dominio 16 La Nación Política
## 3 extinción 16 La Nación Política
## 4 mauricio 13 La Nación Política
## 5 decreto 9 La Nación Política
## 6 presidente 8 La Nación PolíticaLlegado a este punto, lo último que falta hacer es graficar. Pero como descubrí que me gusta tener funciones para todo (¿a quién no?), construí una especifica para usar con estas bases. Lo que hace es captar automáticamente el sitio y la sección de origen (para eso están las columnas en las bases separadas por palabras, además de dejar todo preparado para hacer cruces) y asignarlo como argumentos que se le pasan al gráfico. Lo mismo sucede con la cantidad máxima que deben tener los ejes, que se toman directamente del n con el número más grande.
scrap_wordcount <- function(database){
media_name <- database$site[1]
section_name <- database$section[1]
top_label <- database$n[1]
axislabel <- seq(top_label)
tit <- paste("Conteo de palabras:", media_name)
sub <- paste("Sección:", section_name)
database %>%
arrange(desc(n)) %>%
.[1:20,] %>%
ggplot(., aes(x=word, y=n))+
geom_segment(aes(x=reorder(word, n), xend=word, y=0, yend=n), color="grey")+
geom_point(size=3, color="#d70d2f")+
coord_flip()+
theme_minimal()+
theme(
panel.grid.minor.y = element_blank(),
panel.grid.major.y = element_blank(),
legend.position="none") +
xlab("") +
ylab("Frecuencia")+
labs(title=tit,
subtitle=sub,
caption=Sys.Date())+
scale_y_continuous(breaks=axislabel)
}
scrap_wordcount(`La Nación_Política`)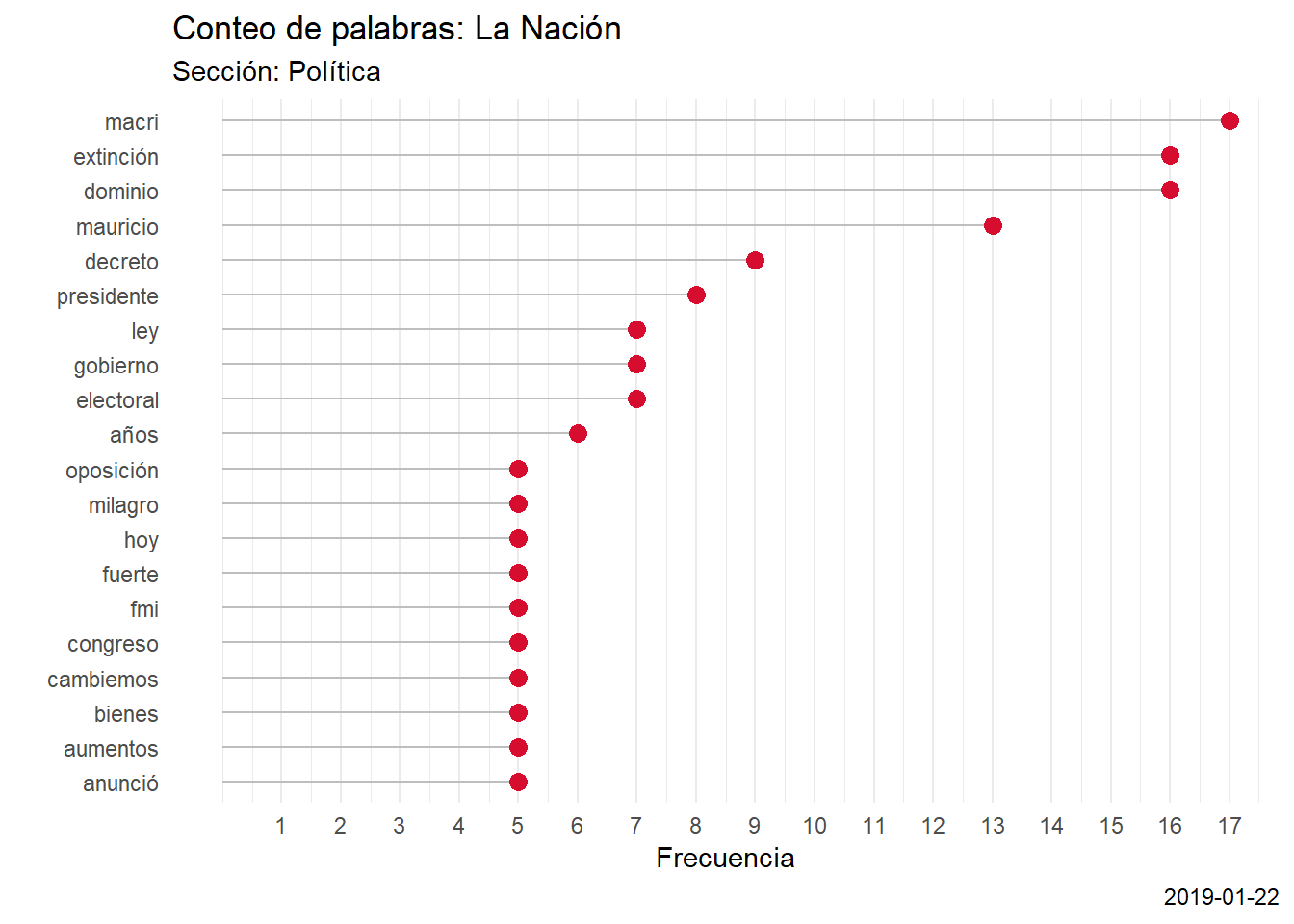
En el margen inferior derecho agregué la fecha: es importante notar que es la fecha de sistema y no la de origen. En otras palabras, es la fecha de creación del gráfico y no de la publicación de la noticia.
La gracia de estas funciones es que con literalmente tres comandos podemos tener un breve pantallazo de lo que más se dice en las secciones de los diarios:
scrap_ln() #levantamos el diario
scrap_word(la_nacion, Economía) #descomponemos la sección en palabras
scrap_wordcount(`La Nación_Economía`) #armamos el gráfico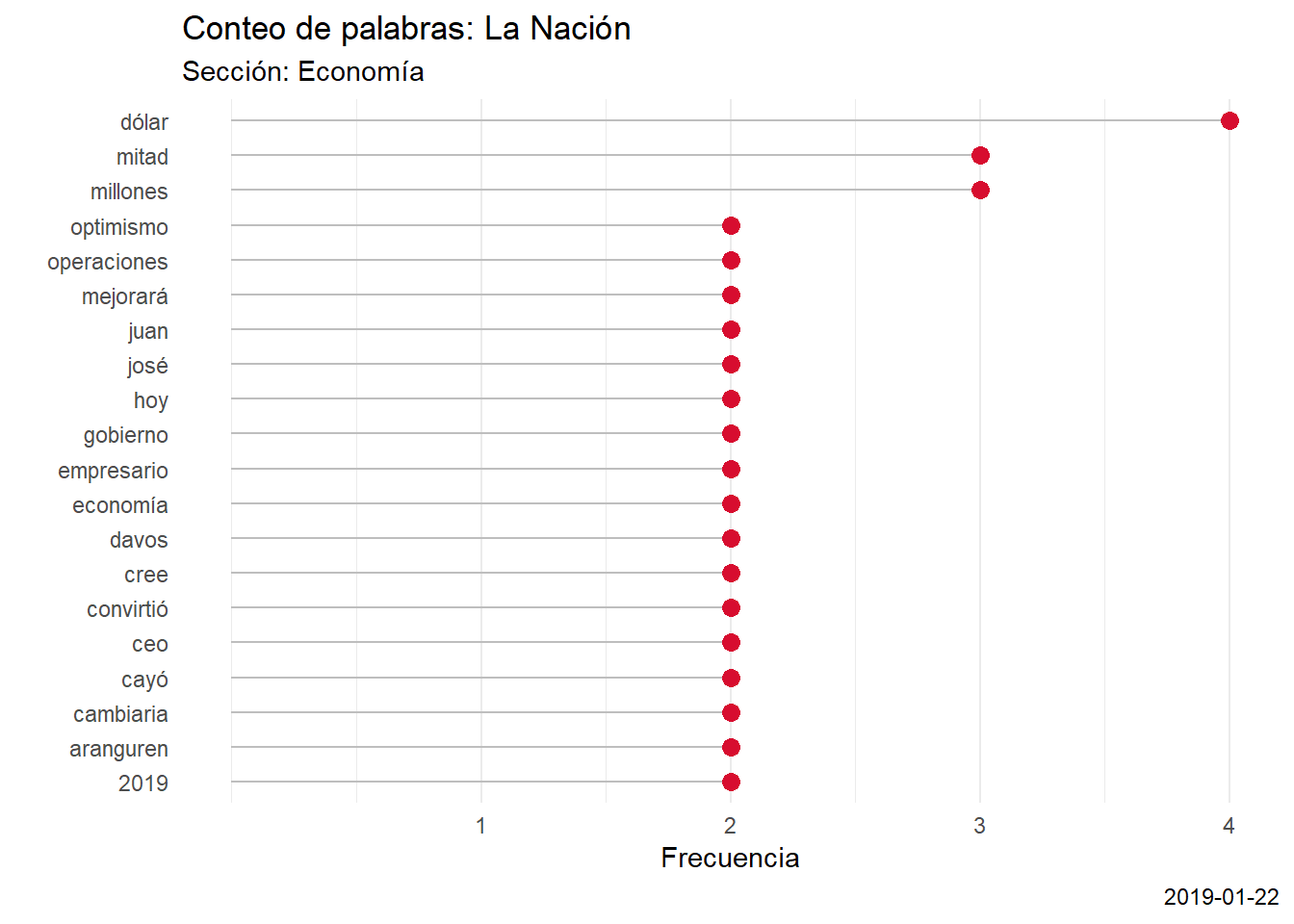
Un toque de distinción para el codeo de los argentinos
En este post les presento estas herramientas que pueden ser muy útiles para analizar los medios de comunicación, cuyo rol en la formación de opinión pública es absolutamente crucial. En futuras entregas voy a analizar qué se dice en cada uno: palabras más importantes y más mencionadas, entre otros.
La información es poder, la desinformación es ejercicio de poder.
