
Uso del Boleto Estudiantil en la Ciudad de Buenos Aires
Encontré un dataset en el Portal Datos Argentina (https://datos.gob.ar) que me permitió sacarme una duda que siempre había tenido desde mis años de estudiante: cuántas personas utilizan el boleto estudiantil en la Ciudad de Buenos Aires. En el dataset están includas más de 43.000 observaciones según año, tipo de pasaje, línea y cantidad de viajes realizados.
Manos a la obra
Arrancamos como siempre con cargar las librerías y la base. Este va a ser un gráfico relativamente sencillo, pero no por eso menos interesante.
library(tidyverse)## -- Attaching packages ------------------------------------------------- tidyverse 1.2.1 --## v ggplot2 3.0.0 v purrr 0.2.5
## v tibble 1.4.2 v dplyr 0.7.6
## v tidyr 0.8.1 v stringr 1.3.1
## v readr 1.1.1 v forcats 0.3.0## -- Conflicts ---------------------------------------------------- tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(ggthemes)
base_pasajes <- read.csv(file = "../../../datasets/cancelaciones_mes_mtipo.csv", sep=";")Lo primero que hay que hacer es mirar la estructura general, y más importante aún, los niveles del tipo de pasaje.
str(base_pasajes)## 'data.frame': 43251 obs. of 4 variables:
## $ ï..anio : Factor w/ 33 levels "01/2016","01/2017",..: 27 27 27 27 27 27 27 27 27 27 ...
## $ linea : Factor w/ 436 levels "BSAS_LINEA_504_ITUZAINGO",..: 1 1 1 1 1 1 2 2 3 3 ...
## $ TipoPasaje: Factor w/ 10 levels "-","ATRIBUTO SOCIAL",..: 3 2 6 9 5 7 2 9 9 2 ...
## $ TOTAL : int 173 8901 487 12730 457 3 523848 1700221 992852 370855 ...levels(base_pasajes$TipoPasaje)## [1] "-" "ATRIBUTO SOCIAL"
## [3] "ESCOLAR" "ESCOLAR INICIAL Y PRIMARIO CABA"
## [5] "ESCOLAR PRIMARIO BSAS" "ESCOLAR SECUNDARIO BSAS"
## [7] "ESCOLAR SECUNDARIO CABA" "ESTUDIANTE"
## [9] "NORMAL" "SIN DEFINIR"Primero, se nota que la primera variable es “año”, y algún tema en la codificación del archivo hace que se vea raro. Por eso hay que cambiarle el nombre para que quede mucho más sencillo de manejar. Luego voy a tomar sólo los que refieren a escolares iniciales, primarios y secundarios de CABA, y con eso voy a agrupar por período y tipo de pasajes para ver cómo se reparten los viajes.
base_pasajes_filtrada <- base_pasajes %>%
rename(periodo = ï..anio) %>%
filter(TipoPasaje==c("ESCOLAR INICIAL Y PRIMARIO CABA", "ESCOLAR SECUNDARIO CABA")) %>%
group_by(periodo, TipoPasaje) %>%
summarise(total=sum(TOTAL)) %>%
mutate(tipo=case_when(TipoPasaje=="ESCOLAR INICIAL Y PRIMARIO CABA"~ "Escolar inicial y primario",
TipoPasaje=="ESCOLAR SECUNDARIO CABA"~ "Escolar secundario"))## Warning in `==.default`(TipoPasaje, c("ESCOLAR INICIAL Y PRIMARIO CABA", :
## longitud de objeto mayor no es múltiplo de la longitud de uno menor## Warning in is.na(e1) | is.na(e2): longitud de objeto mayor no es múltiplo
## de la longitud de uno menorhead(base_pasajes_filtrada)## # A tibble: 6 x 4
## # Groups: periodo [4]
## periodo TipoPasaje total tipo
## <fct> <fct> <int> <chr>
## 1 02/2018 ESCOLAR SECUNDARIO CABA 10 Escolar secundario
## 2 03/2018 ESCOLAR INICIAL Y PRIMARIO CABA 85172 Escolar inicial y primario
## 3 03/2018 ESCOLAR SECUNDARIO CABA 420840 Escolar secundario
## 4 04/2018 ESCOLAR INICIAL Y PRIMARIO CABA 136063 Escolar inicial y primario
## 5 04/2018 ESCOLAR SECUNDARIO CABA 715727 Escolar secundario
## 6 05/2018 ESCOLAR INICIAL Y PRIMARIO CABA 155312 Escolar inicial y primarioAcá vemos algo que podía distorsionar el gráfico: si bien los datos están completos desde marzo a septiembre en el dataset, hay 10 casos aislados en secundarios durante febrero. Dos opciones: o es un error de carga de otro mes, o bien por alguna razón sólo se computaron diez viajes. Sea como sea, hay que sacar esa observación de la visualización para que quede más apropiado.
base_pasajes_filtrada <- base_pasajes %>%
rename(periodo = ï..anio) %>%
filter(TipoPasaje==c("ESCOLAR INICIAL Y PRIMARIO CABA", "ESCOLAR SECUNDARIO CABA")) %>%
group_by(periodo, TipoPasaje) %>%
summarise(total=sum(TOTAL)) %>%
filter(total>10) %>%
mutate(tipo=case_when(TipoPasaje=="ESCOLAR INICIAL Y PRIMARIO CABA"~ "Escolar inicial y primario",
TipoPasaje=="ESCOLAR SECUNDARIO CABA"~ "Escolar secundario"))## Warning in `==.default`(TipoPasaje, c("ESCOLAR INICIAL Y PRIMARIO CABA", :
## longitud de objeto mayor no es múltiplo de la longitud de uno menor## Warning in is.na(e1) | is.na(e2): longitud de objeto mayor no es múltiplo
## de la longitud de uno menorAhora ya está todo en condiciones para graficar. Voy a armar un clásico gráfico de columnas, donde el total de las columnas sea la cantidad de viajes registrados en el período determinado, pero que tenga también una clasificación según su tipo.
ggplot(base_pasajes_filtrada, aes(x=periodo, y=total, fill=tipo))+
geom_col()+
scale_fill_manual(values = c("Escolar inicial y primario"="#662613",
"Escolar secundario"="#2e6d02"),
name="Niveles de escolarización")+
labs(subtitle="Fuente: Ministerio de Transporte, en datos.gob.ar")+
theme_fivethirtyeight()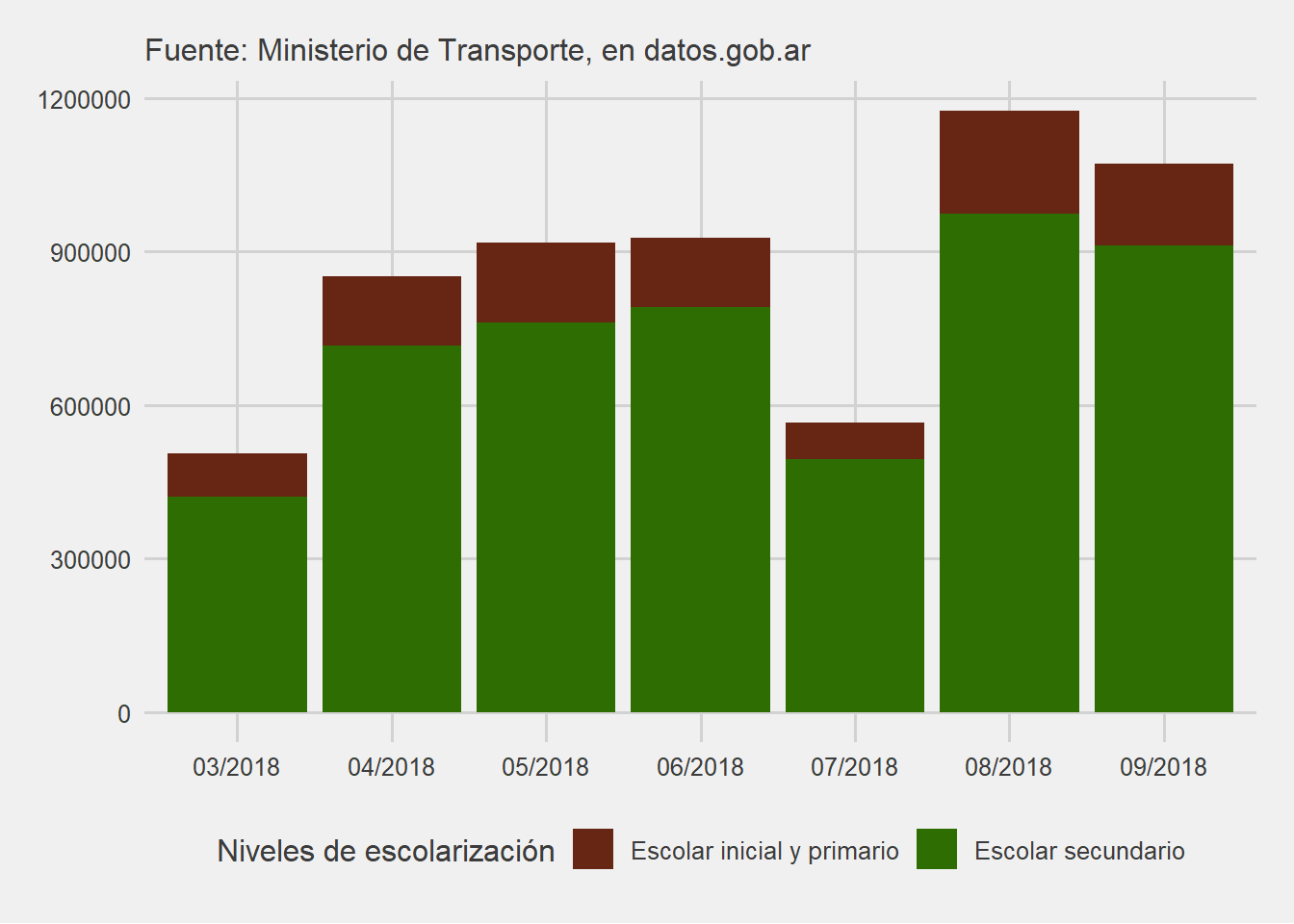
Como se puede observar, la cantidad de viajes registrados por mes es considerable, y es de suponer que el número sea mayor si se contempla quienes acceden desde el Gran Buenos Aires. A mi criterio, esto demuestra la importancia de mantener y garantizar este derecho básico de movilidad que es un elemento clave en el acceso a la educación.
