
Una mirada a la erogación en obras públicas
El portal Buenos Aires Open Data (https://data.buenosaires.gob.ar) tiene un montón de datasets súper interesantes y divertidos para experimentar. En esta ocasión, ví que está disponible uno en el que se relevan las obras públicas a lo largo del año, y decidí ver dónde se concentra la mayor parte de lo erogado.
Manos a la obra
Para empezar, cargo las librerías tidyverse, sf y ggthemes. La primera es la navaja suiza con la que se manipulan bases de datos y se visualizan, dado que incorpora ggplot2. Con el paquete SF tomo la base de los radios censales de la Ciudad Autónoma de Buenos Aires, usando el .geojson alojado en la página de Antonio Vázquez Brust (https://bitsandbricks.github.io/).
library(tidyverse)## -- Attaching packages ------------------------------------------------- tidyverse 1.2.1 --## v ggplot2 3.0.0 v purrr 0.2.5
## v tibble 1.4.2 v dplyr 0.7.6
## v tidyr 0.8.1 v stringr 1.3.1
## v readr 1.1.1 v forcats 0.3.0## -- Conflicts ---------------------------------------------------- tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(sf)## Linking to GEOS 3.6.1, GDAL 2.2.3, proj.4 4.9.3library(ggthemes)
radios <- st_read("https://bitsandbricks.github.io/data/CABA_rc.geojson")## Reading layer `CABA_rc' from data source `https://bitsandbricks.github.io/data/CABA_rc.geojson' using driver `GeoJSON'
## Simple feature collection with 3554 features and 8 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: -58.53092 ymin: -34.70574 xmax: -58.33455 ymax: -34.528
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defsComo lo que estoy buscando es una organización por comunas y no por radios censales, hay que hacer un pequeño reordenamiento:
comunas <- radios %>%
group_by(COMUNA) %>%
summarise(poblacion=sum(POBLACION),
viviendas=sum(VIVIENDAS),
hogares=sum(HOGARES),
hogares_nbi=sum(HOGARES_NBI),
area_km2=sum(AREA_KM2))Ahora toca levantar la base y hacer una agrupación para totalizar el monto de los contratos.
obras <- read.delim("~/Big Data/datasets/observatorio-de-obras-urbanas.csv", encoding = "UTF-8")
obrasencomuna <- obras %>%
mutate(monto_contrato=as.numeric(as.character(monto_contrato))) %>%
filter(monto_contrato!="NA") %>%
group_by(comuna) %>%
summarise(monto=sum(monto_contrato))## Warning in evalq(as.numeric(as.character(monto_contrato)), <environment>):
## NAs introducidos por coerciónComo siempre, gran parte del trabajo consiste en ordenar los datos para que queden de una forma manipulable: que las variables coincidan en mayúsculas y minúsculas y que las necesarias sean tomadas como un factor y no como una variable categórica. Una vez que eso está listo, podemos combinar ambas tablas por su elemento común Entonces:
comunas_2 <- comunas %>%
mutate(comuna=COMUNA) %>%
select(-COMUNA)
obrasencomuna <- obrasencomuna %>%
mutate(comuna=as.factor(comuna))
base_final<- left_join(comunas_2, obrasencomuna)## Joining, by = "comuna"## Warning: Column `comuna` joining factors with different levels, coercing to
## character vectorhead(base_final)## Simple feature collection with 6 features and 7 fields
## geometry type: POLYGON
## dimension: XY
## bbox: xmin: -58.53092 ymin: -34.64626 xmax: -58.33925 ymax: -34.528
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defs
## # A tibble: 6 x 8
## poblacion viviendas hogares hogares_nbi area_km2 comuna monto
## <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <dbl>
## 1 205886 131382 84468 13429 17.8 1 1.35e10
## 2 166022 71664 61453 2149 12.6 10 6.22e 8
## 3 189832 84734 71460 1444 14.1 11 4.38e 8
## 4 200116 93502 78547 1335 15.6 12 8.26e 8
## 5 230767 129482 100257 1879 14.4 13 2.46e 9
## 6 226534 141710 103167 2425 16.0 14 4.47e 8
## # ... with 1 more variable: geometry <POLYGON [°]>Ahora que tengo la base lista, es momento de graficar. Acá se me ocurrió también incorporar el trazado de la línea de subtes de la ciudad al esquema porque me imaginaba que iba a arrojar datos interesantes.
subte_lineas <- st_read("http://bitsandbricks.github.io/data/subte_lineas.geojson")## Reading layer `subte_lineas' from data source `http://bitsandbricks.github.io/data/subte_lineas.geojson' using driver `GeoJSON'
## Simple feature collection with 80 features and 2 fields
## geometry type: MULTILINESTRING
## dimension: XY
## bbox: xmin: -58.48639 ymin: -34.64331 xmax: -58.36993 ymax: -34.55564
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defssubte_estaciones <- st_read("http://bitsandbricks.github.io/data/subte_estaciones.geojson")## Reading layer `subte_estaciones' from data source `http://bitsandbricks.github.io/data/subte_estaciones.geojson' using driver `GeoJSON'
## Simple feature collection with 86 features and 3 fields
## geometry type: POINT
## dimension: XY
## bbox: xmin: -58.48639 ymin: -34.64331 xmax: -58.36993 ymax: -34.55564
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defsggplot()+geom_sf(data=base_final, aes(fill=monto))+
scale_fill_viridis_c(direction=-1, option = "A", name="Millones de pesos", breaks=c(174215685, 3513493136, 6852770588, 10192048039, 13531325491), labels=c("174", "3.500", "6.800","10.000", "13.500"))+
geom_sf(data = subte_lineas, color="red")+
geom_sf(data = subte_estaciones, color="grey")+
labs(title="Erogación en obra pública por Comunas en la Ciudad de Buenos Aires",
subtitle="Año 2018",
caption="Fuente: Portal Buenos Aires Data, data.buenosaires.gob.ar")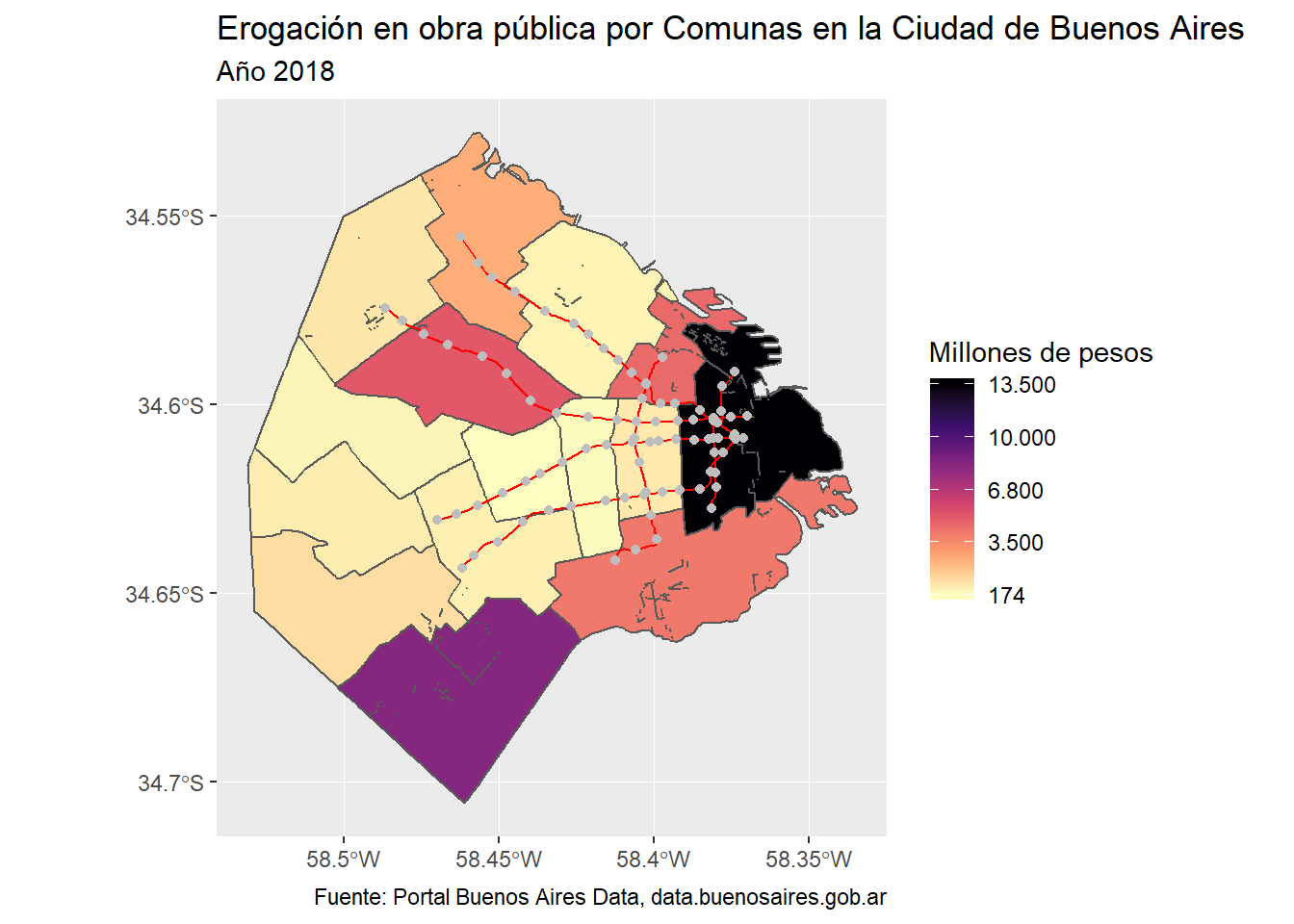
Como se observa en este gráfico, aún hay muchísimo que hacer en materia de descentralización para que las obras públicas lleguen a toda la ciudad. Hay una gran concentración en la zona más céntrica, así como también un presupuesto relativamente alto en la zona sur. Mucho también tiene que ver con la ejecución de las obras para los Juegos Olímpicos de la Juventud 2018.
Profundizando
Esta imagen la había posteado originalmente en mi LinkedIn. Ahí alguien la vio (es impresionante como estas cosas llegan a ojos de profesionales que uno no conoce) y me hizo una pregunta técnica y otra de visión general: qué tipos de obras eran y por qué yo creía que descentralizar es importante. Así que me puse manos a la obra: primero, reorganizando la base original en función del tipo de erogación y luego graficando.
erogacion_tipo <- obras %>%
mutate(monto_contrato=as.numeric(as.character(monto_contrato))) %>%
filter(monto_contrato!="NA") %>%
group_by(tipo) %>%
summarise(monto=sum(monto_contrato))## Warning in evalq(as.numeric(as.character(monto_contrato)), <environment>):
## NAs introducidos por coerciónggplot(data=erogacion_tipo, aes(x=tipo, weight=monto, fill=tipo))+
geom_bar()+
labs(title="Erogación en obra pública según tipo en la Ciudad de Buenos Aires",
subtitle="Año 2018",
caption="Fuente: Portal Buenos Aires Data, data.buenosaires.gob.ar",
x="Tipo de obra",
y="Monto erogado en millones de pesos",
fill="Tipo")+
scale_y_continuous(breaks=c(5000000000, 10000000000, 15000000000),
labels=c("5000", "10.000", "15.000"))+
scale_fill_gdocs()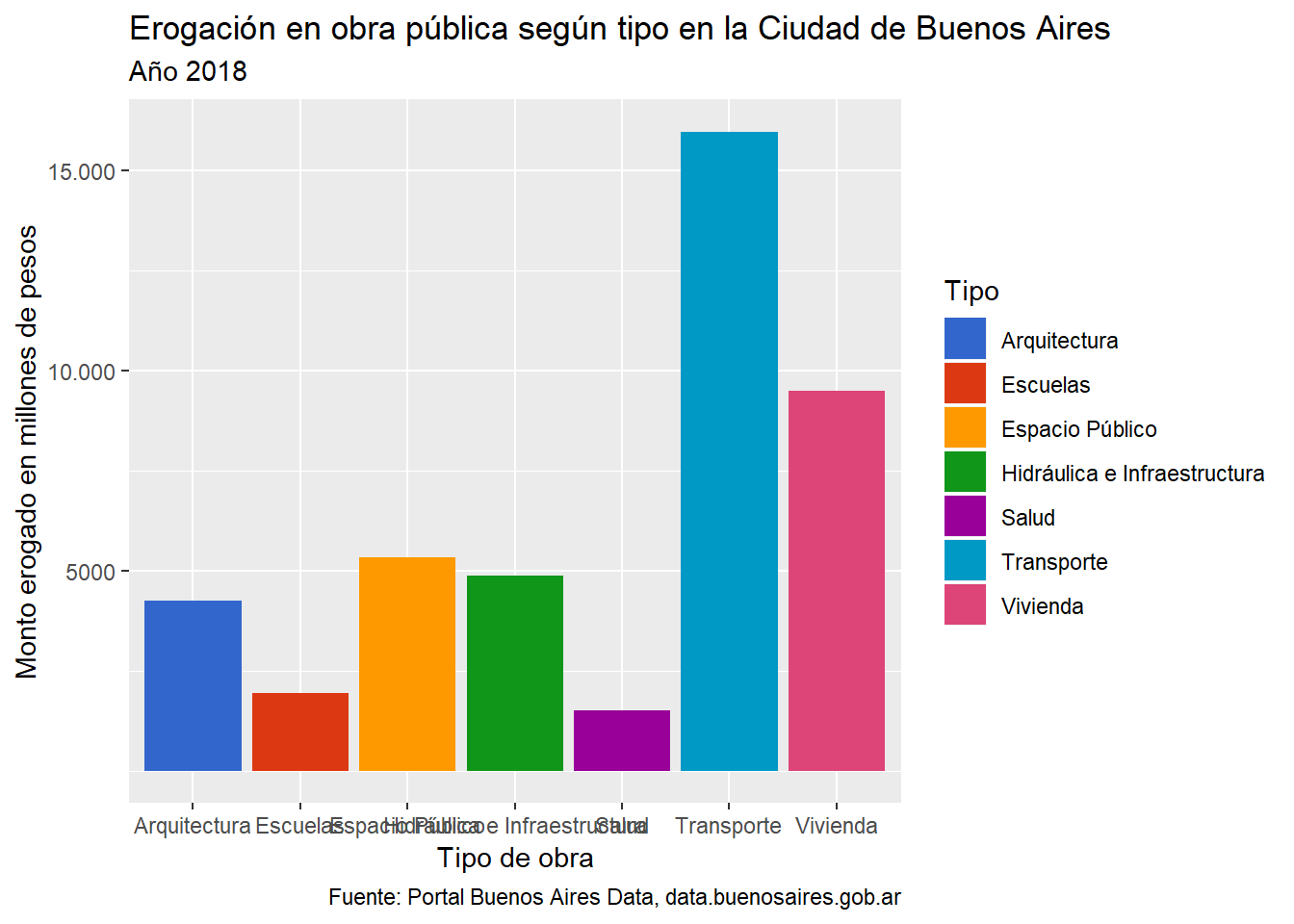
Este gráfico reafirma -a mi criterio- aún más la importancia de descentralizar. Como se puede observar, la amplia mayoría de los gastos están vinculados a Transporte, gastos que representan prácticamente la suma de Vivienda, Escuelas y Salud. En este punto, también es importante considerar que la inversión en las obras para los JJ.OO sumaron más de 3.600 millones de pesos.
Si complementamos este gráfico con el primero, podemos inferir que la gran parte de la obra pública está destinada principalmente a facilitar la movilidad entre algunos puntos neurálgicos de acceso a la Capital. Hay mucho que puede hacerse aún, observando estos datos, para mejorar la inversión y ayudar a mejorar la calidad de vida de todos los porteñxs.
