
Test de Relaciones Violentas: se encienden las alarmas
Entre las iniciativas del Gobierno de la Ciudad de Buenos Aires se encuentra el Test de Alerta sobre un Noviazgo Violento. Como bien explican en la presentación del dataset, la violencia de género no es sólo agresiones físicas y sexuales: la cotidianidad en las relaciones muchas veces encierra otra clase de violencia, un poco más sutil, pero no por ello menos peligrosa.
El test consta de 15 preguntas donde se busca identificar situaciones de la vida cotidiana donde pueda expresarse esta problemática: si la pareja revisa los mensajes del celular, si prohibe el uso de una vestimenta, si insulta. En definitiva, si impide una vida digna e independiente haciendo ejercicio de una violencia simbólica.
Ante ese cuestionario autoadministrado que presenta situaciones hipotéticas, quien responde debe contestar con A (siempre), B (a veces) o C (nunca). De acuerdo al Ministerio de Desarrollo Humano y Hábitat, una mayoría de A indica una relación violenta, una primacía de B evidencia señales de alarma y si predomina la C se trata de un noviazgo saludable. Esta base cuenta con casi 4.000 respuestas y son datos que comprenden resultados entre febrero y octubre de este año.
Lo que vamos a hacer es desagregar los resultados por barrio y observaremos cuántas relaciones tienen mayoría de A o B, detectando así las relaciones que, al menos, presentan señales de alarma de violencia. Luego haremos dos gráficos: el primero mostrará los resultados por barrios, y vamos a agregarle la ubicación geográfica de los Centros Integrales de la Mujer, espacios donde busca darse contención a aquellas que sean violentadas por sus parejas. El segundo será un reparto por edad de los resultados.
Manos a la obra
Como siempre, cargamos tidyverse para manipular y ordenar los datos, y sf para trabajar con datos georeferenciados y luego levantamos la base.
library(tidyverse)## -- Attaching packages ------------------------------------------------- tidyverse 1.2.1 --## v ggplot2 3.0.0 v purrr 0.2.5
## v tibble 1.4.2 v dplyr 0.7.6
## v tidyr 0.8.1 v stringr 1.3.1
## v readr 1.1.1 v forcats 0.3.0## -- Conflicts ---------------------------------------------------- tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(sf)## Linking to GEOS 3.6.1, GDAL 2.2.3, proj.4 4.9.3test_alerta <- read.csv('../../../datasets/resultados-del-test-febrero-octubre-2018.csv', encoding = "UTF-8")
str(test_alerta)## 'data.frame': 3910 obs. of 18 variables:
## $ fecha : Factor w/ 240 levels "2018-02-14","2018-02-15",..: 240 240 239 239 239 239 239 239 238 238 ...
## $ hora : Factor w/ 1251 levels "00:00:00","00:01:00",..: 609 50 1240 791 790 646 526 452 993 982 ...
## $ edad : int 19 21 16 17 32 35 22 28 21 24 ...
## $ genero : Factor w/ 3 levels "Hombre","Mujer",..: 2 1 2 2 2 2 2 2 2 2 ...
## $ barrio : Factor w/ 48 levels "Agronomia","Almagro",..: 22 22 22 22 32 6 2 25 20 3 ...
## $ pregunta_1 : Factor w/ 3 levels "A","B","C": 3 2 2 1 2 3 2 3 1 3 ...
## $ pregunta_2 : Factor w/ 3 levels "A","B","C": 3 3 3 1 2 3 3 3 2 3 ...
## $ pregunta_3 : Factor w/ 3 levels "A","B","C": 3 3 2 1 1 3 2 3 2 3 ...
## $ pregunta_4 : Factor w/ 3 levels "A","B","C": 3 3 1 1 1 2 3 3 1 3 ...
## $ pregunta_5 : Factor w/ 3 levels "A","B","C": 3 3 3 2 1 3 3 2 2 3 ...
## $ pregunta_6 : Factor w/ 3 levels "A","B","C": 3 3 2 2 1 3 3 3 3 3 ...
## $ pregunta_7 : Factor w/ 3 levels "A","B","C": 3 2 1 2 2 3 3 3 2 3 ...
## $ pregunta_8 : Factor w/ 3 levels "A","B","C": 3 3 2 3 2 3 3 3 3 3 ...
## $ pregunta_9 : Factor w/ 3 levels "A","B","C": 3 3 3 3 2 3 3 3 3 3 ...
## $ pregunta_10: Factor w/ 3 levels "A","B","C": 3 3 3 2 3 3 3 3 3 3 ...
## $ pregunta_11: Factor w/ 3 levels "A","B","C": 3 3 1 1 2 3 3 3 1 3 ...
## $ pregunta_12: Factor w/ 3 levels "A","B","C": 3 3 1 2 2 3 2 3 1 3 ...
## $ pregunta_13: Factor w/ 3 levels "A","B","C": 3 3 1 3 1 3 3 3 2 3 ...Podemos ver que la base tiene datos demográficos de barrio, edad y género, entre otros. Al igual que en el post de la erogación en obras públicas, tomamos el radio censal que hostea Antonio Vázquez Brust en su blog Bits and Bricks, y usamos esos datos georeferenciados para hacer el recorte, esta vez por barrios.
radios <- st_read("https://bitsandbricks.github.io/data/CABA_rc.geojson")## Reading layer `CABA_rc' from data source `https://bitsandbricks.github.io/data/CABA_rc.geojson' using driver `GeoJSON'
## Simple feature collection with 3554 features and 8 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: -58.53092 ymin: -34.70574 xmax: -58.33455 ymax: -34.528
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defsbarrios <- radios %>%
group_by(BARRIO) %>%
summarise(poblacion=sum(POBLACION),
viviendas=sum(VIVIENDAS),
hogares=sum(HOGARES),
hogares_nbi=sum(HOGARES_NBI),
area_km2=sum(AREA_KM2))
str(barrios)## Classes 'sf', 'tbl_df', 'tbl' and 'data.frame': 48 obs. of 7 variables:
## $ BARRIO : Factor w/ 48 levels "AGRONOMIA","ALMAGRO",..: 1 2 3 4 5 6 7 8 9 10 ...
## $ poblacion : num 13912 131699 138926 89452 126267 ...
## $ viviendas : num 6262 71216 77981 33058 71363 ...
## $ hogares : num 5284 58327 60387 31249 54666 ...
## $ hogares_nbi: num 70 3404 7122 3850 542 ...
## $ area_km2 : num 2.12 4.05 4.34 7.96 7.73 ...
## $ geometry :sfc_GEOMETRY of length 48; first list element: List of 1
## ..$ : num [1:107, 1:2] -58.5 -58.5 -58.5 -58.5 -58.5 ...
## ..- attr(*, "class")= chr "XY" "POLYGON" "sfg"
## - attr(*, "sf_column")= chr "geometry"
## - attr(*, "agr")= Factor w/ 3 levels "constant","aggregate",..: NA NA NA NA NA NA
## ..- attr(*, "names")= chr "BARRIO" "poblacion" "viviendas" "hogares" ...En la base vimos que las preguntas están cada una en una columna separada. A efectos de agrupar las respuestas, necesitamos aplicar un gather: tener en una columna qué numero de pregunta es y en otra el valor que asignó quien respondió.
test_gather <- test_alerta %>%
gather(pregunta, valor, c(pregunta_1:pregunta_13))
head(test_gather)## fecha hora edad genero barrio pregunta valor
## 1 2018-10-11 12:58:00 19 Mujer Otro pregunta_1 C
## 2 2018-10-11 00:51:00 21 Hombre Otro pregunta_1 B
## 3 2018-10-10 23:48:00 16 Mujer Otro pregunta_1 B
## 4 2018-10-10 16:03:00 17 Mujer Otro pregunta_1 A
## 5 2018-10-10 16:02:00 32 Mujer San Cristóbal pregunta_1 B
## 6 2018-10-10 13:35:00 35 Mujer Boedo pregunta_1 CAhora que tenemos los datos juntos, el paso que sigue es hacer las tasas de respuestas por barrio.
test_tasa <- test_gather %>%
group_by(barrio) %>%
summarise(preguntasa=sum(valor=="A")/sum(valor%in%c("A", "B", "C")),
preguntasb=sum(valor=="B")/sum(valor%in%c("A", "B", "C")),
preguntasc=sum(valor=="C")/sum(valor%in%c("A", "B", "C")))
head(test_tasa)## # A tibble: 6 x 4
## barrio preguntasa preguntasb preguntasc
## <fct> <dbl> <dbl> <dbl>
## 1 Agronomia 0.256 0.286 0.459
## 2 Almagro 0.256 0.299 0.445
## 3 Balvanera 0.222 0.266 0.512
## 4 Barracas 0.212 0.312 0.476
## 5 Belgrano 0.195 0.283 0.521
## 6 Boedo 0.175 0.326 0.499El fino arte del data wrangling
Ya empieza a asomar el primer problema: las bases que contienen los nombres de los barrios están en distinto formato. Por eso primero hay que pasar todo a minúscula, tanto lo que contiene la variable “barrio” como el nombre en sí. Una vez que está listo, unimos ambas bases.
test_tasa <- test_tasa %>%
mutate(barrio=tolower(barrio))
barrios <- barrios %>%
mutate(BARRIO=tolower(BARRIO)) %>%
rename(barrio=BARRIO)
tasa_barrios <- left_join(barrios, test_tasa, by="barrio")
head(tasa_barrios)## Simple feature collection with 6 features and 9 fields
## geometry type: GEOMETRY
## dimension: XY
## bbox: xmin: -58.50294 ymin: -34.66295 xmax: -58.33455 ymax: -34.53199
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defs
## # A tibble: 6 x 10
## barrio poblacion viviendas hogares hogares_nbi area_km2 preguntasa
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 agron~ 13912 6262 5284 70 2.12 0.256
## 2 almag~ 131699 71216 58327 3404 4.05 0.256
## 3 balva~ 138926 77981 60387 7122 4.34 0.222
## 4 barra~ 89452 33058 31249 3850 7.96 0.212
## 5 belgr~ 126267 71363 54666 542 7.73 0.195
## 6 boca 45113 18133 16287 3460 5.02 NA
## # ... with 3 more variables: preguntasb <dbl>, preguntasc <dbl>,
## # geometry <GEOMETRY [°]>¡No tan rápido! Resulta que los mismos nombres de los barrios también están escritos de distinta manera: con y sin tilde, con y sin artículos, e inclusive en el caso del barrio de Santa Rita, en la base de las tasas figura como “otro”. Así que a unificar criterios se ha dicho.
test_tasa2 <- test_tasa %>%
mutate(barrio=case_when(barrio=="agronomia"~"agronomía",
barrio=="boca"~ "la boca",
barrio=="nuñez"~"núñez",
barrio=="villa general mitre"~"villa gral. mitre",
barrio=="la paternal"~ "paternal",
barrio=="otro"~ "villa santa rita",
barrio=="montserrat"~ "monserrat",
TRUE~ barrio))
barrios2 <- barrios %>%
mutate(barrio=case_when(barrio=="agronomia"~"agronomía",
barrio=="boca"~ "la boca",
barrio=="san cristobal"~ "san cristóbal",
barrio=="san nicolas"~ "san nicolás",
barrio=="villa ortuzar"~ "villa ortúzar",
barrio=="villa pueyrredon"~ "villa pueyrredón",
barrio=="constitucion"~ "constitución",
barrio=="nuñez"~ "núñez",
barrio=="velez sarsfield"~ "vélez sarsfield",
TRUE~ barrio))
tasa_barrios2 <- left_join(test_tasa2, barrios2, by="barrio")
base_final <- tasa_barrios2 %>%
mutate(preguntasab=preguntasa+preguntasb)El último paso que hice fue sumar los resultados de las tasas de A y B, para tener la línea sobre la cual graficar. Ahora que ya está todo listo, sólo resta levantar la base que contiene los puntos geográficos de los Centros Integrales de la Mujer y colocar esa como la segunda capa del gráfico.
centros_mujer <- read.csv('../../../datasets/centros-integrales-de-la-mujer.csv')
ggplot()+
geom_sf(data=base_final, aes(fill=preguntasab))+
scale_fill_continuous(low = "#34a853", high = "#ea4335", name="Porcentaje",
breaks=c(0.33, 0.47, 0.61),
labels=c("33%", "47%", "61%"))+
labs(title="Porcentaje de relaciones violentas o con señales de alarma",
subtitle="Año 2018",
caption="Fuente: Portal Buenos Aires Data, data.buenosaires.gob.ar")+
geom_point(data = centros_mujer, aes(x=X, y=Y), color="white")+
theme(axis.text.x = element_blank(),
axis.text.y = element_blank(),
axis.title.x = element_blank(),
axis.title.y = element_blank(),
axis.ticks.x = element_blank(),
axis.ticks.y = element_blank(),
rect = element_blank())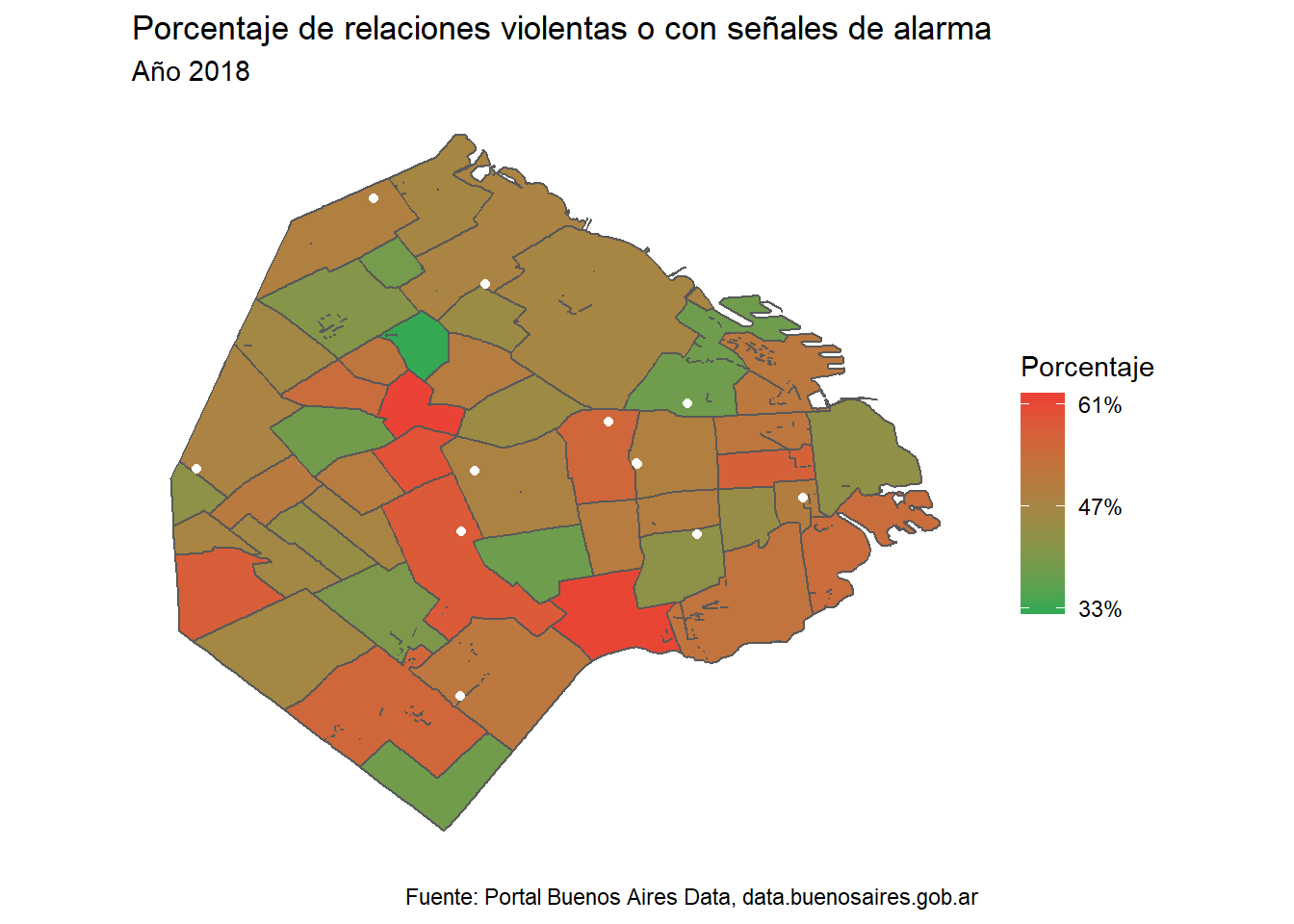
El resultado sin duda es alarmante: hay elevadísimos promedios de relaciones con indicios de violencia en la Ciudad de Buenos Aires, donde predomina Paternal (61,8%), Pompeya (61,5%) y Villa General Mitre (59,6%). Es escalofriante tomar dimensión de estos números: en estos barrios, tres de cada cinco parejas presenta estos signos. Si miramos los barrios que tienen mayorías de A, el podio lo encabeza nuevamente Paternal (28,6%), seguido de San Nicolás (28,4%) y Pompeya (27,3%).
El reparto de los Centros Integrales de la Mujer muestra que están ubicados mayoritariamente en barrios de “violencia media”, por ponerle un nombre. Sería interesante saber si la presencia de estos Centros hizo caer ese porcentaje en los barrios: de todos modos, el gráfico evidencia dónde tendría que haber una mayor contención estatal para colaborar con la erradicación de la violencia.
Para el gráfico por edad, tenemos que reacomodar toda la base de acuerdo a los nuevos criterios. Al observar lo que sucede dentro de esa variable encontramos que hay resultados que llaman la atención: edades que parecieran malas respuestas (nos cuesta creer que haya respondido una persona de 4 años, por ejemplo), pero para datos que podríamos calificar como “inverosímiles”, creamos una categoría “otros”. Metamos quinta a fondo y veamos qué pasa:
base_franja <- test_gather %>%
mutate(barrio=tolower(barrio)) %>%
mutate(barrio=case_when(barrio=="agronomia"~"agronomía",
barrio=="boca"~ "la boca",
barrio=="nuñez"~"núñez",
barrio=="villa general mitre"~"villa gral. mitre",
barrio=="la paternal"~ "paternal",
barrio=="otro"~ "villa santa rita",
barrio=="montserrat"~ "monserrat",
TRUE~ barrio)) %>%
mutate(franja=case_when(edad%in%c(12:18)~"12 a 18",
edad%in%c(19:25)~"19 a 25",
edad%in%c(26:35)~"26 a 35",
edad%in%c(36:45)~"36 a 45",
edad%in%c(46:55)~"46 a 55",
edad%in%c(56:76)~"56 a 76",
TRUE~ "otros")) %>%
group_by(franja) %>%
summarise(preguntasa=sum(valor=="A")/sum(valor%in%c("A", "B", "C")),
preguntasb=sum(valor=="B")/sum(valor%in%c("A", "B", "C")),
preguntasc=sum(valor=="C")/sum(valor%in%c("A", "B", "C")))
base_franja_graf <- base_franja %>%
gather(pregunta, valor, c(2:4))
ggplot(base_franja_graf, aes(franja, valor, fill=pregunta))+
geom_col()+
scale_fill_brewer(palette="Set1", name="Respuestas",
labels=c("A", "B", "C"))+
labs(title="Porcentaje de respuestas al Test de Relaciones Violentas según edad",
subtitle="Año 2018",
caption="Fuente: Portal Buenos Aires Data, data.buenosaires.gob.ar")+
theme(axis.title.x = element_blank(),
axis.title.y = element_blank(),
rect = element_blank())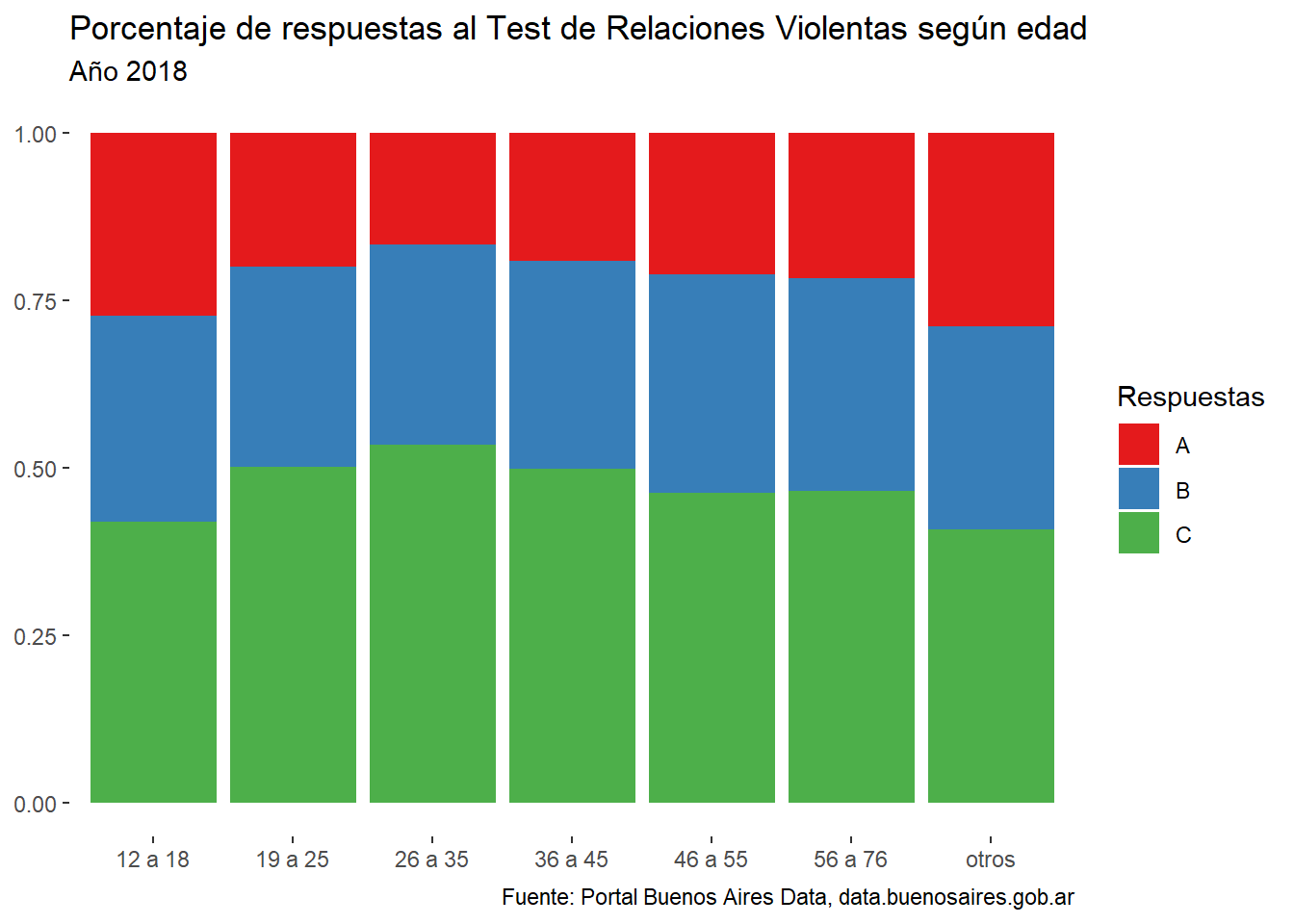
Los resultados muestran que quienes tienen entre 26 y 35 años tienen relaciones más saludables, con una minoría de respuestas A (16,6%) y mayoría de C (50,1%). Por otro lado es alarmante lo que se observa en la franja preadolescente: ostenta la mayor proporción de respuestas con alarmas (57,9%), con lo que sólo cuatro de cada diez relaciones en esa edad tienen características saludables. Esto refuerza la importancia de que haya políticas sociales como la ley de Educación Sexual Integral (ESI), que hacen posible la detección de estas señales de violencia simbólica desde una temprana edad.
