
Mirá como nos ponemos: una mirada a la twittósfera
Es claro que el movimiento de mujeres llegó para quedarse (y en buena hora). En estos últimos días, la denuncia de la actriz Thelma Fardín generó una oleada más que necesaria donde muchas mujeres se sintieron lo suficientemente acompañadas y empoderadas para hacer lo propio con otros hombres que las han violentado o abusado. Como hombre, me genera una auténtica repulsión saber que hay congéneres capaces de hacer atrocidades semejantes y desde mi humilde lugar como sociólogo y analista no puedo hacer gran cosa salvo dar la batalla donde corresponde: deconstruir propias prácticas y micromachismos, así como también instar a otros hombres a que hagan lo propio.
Me pareció interesante hacer una lectura sobre lo que sucede en Twitter con esta oleada verde para ver qué es lo que se dice, y así, profundizar un poco lo estudiado en el post anterior (https://hernanescu.github.io/2018/12/maquina-scrapear/) para ver qué es lo que devuelve la red social al momento de scrapear sus datos.
Manos a la obra
Arrancamos como siempre cargando librerías. En esta oportunidad van a ser unas cuantas, así que me parece un poco más ordenado cargar todas las que voy a usar (donde están tidyverse, twitteR, tidytext y las clásicas de gráficos) y cuando utilice alguna un poco más específica mencionarla ahí mismo.
library(tidyverse)## -- Attaching packages ------------------------------------------------- tidyverse 1.2.1 --## v ggplot2 3.0.0 v purrr 0.2.5
## v tibble 1.4.2 v dplyr 0.7.6
## v tidyr 0.8.1 v stringr 1.3.1
## v readr 1.1.1 v forcats 0.3.0## -- Conflicts ---------------------------------------------------- tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(twitteR)##
## Attaching package: 'twitteR'## The following objects are masked from 'package:dplyr':
##
## id, locationlibrary(tidytext)
library(tm)## Loading required package: NLP##
## Attaching package: 'NLP'## The following object is masked from 'package:ggplot2':
##
## annotatelibrary(wordcloud2)
library(webshot)
library(htmlwidgets)
library(wordcloud2)
library(ggwordcloud)
library(hrbrthemes)## NOTE: Either Arial Narrow or Roboto Condensed fonts are *required* to use these themes.## Please use hrbrthemes::import_roboto_condensed() to install Roboto Condensed and## if Arial Narrow is not on your system, please see http://bit.ly/arialnarrowlibrary(ggthemes)
library(forcats)Al igual que en el post pasado, todos los datos de la cuenta de Twitter son personales y privados, por lo que este paso sigue quedando oculto.
Ahora toca cargar las funciones de búsqueda. Aunque sólo voy a usar tw_search, dejo la de los timelines también por si alguien está leyendo esto por primera vez. En el post anterior de scrapeo está mejor explicado cómo las construí, pero son bastante sencillas, como se aprecia a simple vista.
# Función 1: tw_search 0.3 ----------------------------------------------------
tw_search <- function(x, cant){
terminos <- deparse(substitute(x))
terminos_h <- paste0("#", terminos)
json <- searchTwitter(terminos_h, n=cant)
base <- twListToDF(json)
assign(x=terminos, value = base, pos=1)
}
# Función 2: tw_search_timelines 0.1 --------------------------------------
tw_search_timelines <- function(x, cant) {
terminos <- deparse(substitute(x))
json <- userTimeline(terminos, n=cant)
base <- twListToDF(json)
assign(x=terminos, value = base, pos=1)
}Una muy linda herramienta que encontré con un gran aporte de los colegas analistas de la comunidad R en Baires (https://renbaires.github.io/) es un léxico realiado de manera nativa en castellano para la clasificación de ciertas palabras en términos de positivas y negativas. Son más de 2800 palabras, clasificadas del 1 al 3, donde 1 es negativo y 3 es positivo. Quien quiera conocer más sobra esta investigación, le dejo el link: http://habla.dc.uba.ar/gravano/sdal.php.
Así que una vez cargado ese diccionario, vamos a hacer la búsqueda de #miracomonosponemos, seleccionando unos 5000 tweets. Con cada post sigo tensando un poco más la cuerda a ver hasta dónde me permite buscar: la vez pasada había hecho casi 2000 en una sola búsqueda, así que ¡veamos si nos permite!
sdal <- read.csv('https://hernanescu.github.io/data/SDAL.csv')
tw_search(miracomonosponemos, 5000)¡Perfecto! Tenemos una buena base para trabajar. La primera pregunta que se me viene es: estos 5000 tweets, ¿cuánto tiempo representa?
miracomonosponemos %>%
arrange(created) %>%
select(created) %>%
filter(row_number()==1 | row_number()==5000)## created
## 1 2018-12-19 04:21:16
## 2 2018-12-19 20:36:58En una temática tan presente como esta, era esperable: tenemos una fotografía que captura sólo 18 horas de movimiento. No está mal, pero acá ya aprendimos una lección: si se quiere analizar un fenómeno desde su nacimiento, lo que hay que hacer es estar sumamente atento e ir corriendo búsquedas de forma periódica y guardar los resultados para procesarlos.
Lo que quiero hacer es ver los tweets más populares para ver qué fue lo que más resonó: se me ocurre que una buena forma de estudiarlo es ver los más retweeteados.
miracomonosponemos %>%
arrange(desc(retweetCount)) %>%
select(screenName, text) %>%
head()## screenName
## 1 lokapsi
## 2 LuSolis7
## 3 CarlaPardo__
## 4 mbinet_
## 5 Byron_Rosales
## 6 IvannaZL
## text
## 1 RT @MartuCattoni: Hoy me subí al colectivo, estaba sola. Una parada despues se suben un par de personas. Una de ellas, una señora de al red…
## 2 RT @MartuCattoni: Hoy me subí al colectivo, estaba sola. Una parada despues se suben un par de personas. Una de ellas, una señora de al red…
## 3 RT @MartuCattoni: Hoy me subí al colectivo, estaba sola. Una parada despues se suben un par de personas. Una de ellas, una señora de al red…
## 4 RT @soythelmafardin: #MiraComoNosPonemos \nhttps://t.co/SROsqj8DWk
## 5 RT @magalitajes: #MiraComoNosPonemos\nLa mierda de Darthes no es un caso aislado, está avalado por un sistema que encubre, defiende y perpet…
## 6 RT @magalitajes: #MiraComoNosPonemos\nLa mierda de Darthes no es un caso aislado, está avalado por un sistema que encubre, defiende y perpet…Acá podemos ver que entre lo que nos devuelve Twitter hay muchos repetidos, que son los más populares. Hagamos entonces un subset, tomando un elemento por conteo de retweets, de forma tal de quedarnos con un solo elemento.
mira_unique <- miracomonosponemos %>%
subset(!duplicated(text))
mira_unique %>%
arrange(desc(retweetCount)) %>%
head()## text
## 1 RT @MartuCattoni: Hoy me subí al colectivo, estaba sola. Una parada despues se suben un par de personas. Una de ellas, una señora de al red…
## 2 RT @soythelmafardin: #MiraComoNosPonemos \nhttps://t.co/SROsqj8DWk
## 3 RT @magalitajes: #MiraComoNosPonemos\nLa mierda de Darthes no es un caso aislado, está avalado por un sistema que encubre, defiende y perpet…
## 4 RT @natijota: Ni por borracha, ni por andar con poca ropa, ni por “buscona”, ni “por puta”. Si no hay un explícito “sí”, ES NO. Si es menor…
## 5 RT @riverocalu: #Miracomonosponemos https://t.co/Jtuibl5Awy
## 6 RT @malefilmica: #MiraComoNosPonemos\n\nhoy me levanté a las 10 como todas las mañanas, le mandé los buenos días a mi novio y me puse a ver v…
## favorited favoriteCount replyToSN created truncated
## 1 FALSE 0 <NA> 2018-12-19 18:25:18 FALSE
## 2 FALSE 0 <NA> 2018-12-19 16:00:05 FALSE
## 3 FALSE 0 <NA> 2018-12-19 15:42:37 FALSE
## 4 FALSE 0 <NA> 2018-12-19 20:05:00 FALSE
## 5 FALSE 0 <NA> 2018-12-19 17:06:41 FALSE
## 6 FALSE 0 <NA> 2018-12-19 20:34:14 FALSE
## replyToSID id replyToUID
## 1 <NA> 1075457058621788160 <NA>
## 2 <NA> 1075420512501841920 <NA>
## 3 <NA> 1075416117504548870 <NA>
## 4 <NA> 1075482150600892416 <NA>
## 5 <NA> 1075437276019286016 <NA>
## 6 <NA> 1075489507925995524 <NA>
## statusSource
## 1 <a href="http://twitter.com/download/iphone" rel="nofollow">Twitter for iPhone</a>
## 2 <a href="http://twitter.com" rel="nofollow">Twitter Web Client</a>
## 3 <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a>
## 4 <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a>
## 5 <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a>
## 6 <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a>
## screenName retweetCount isRetweet retweeted longitude latitude
## 1 lokapsi 22736 TRUE FALSE NA NA
## 2 mbinet_ 18983 TRUE FALSE NA NA
## 3 Byron_Rosales 18175 TRUE FALSE NA NA
## 4 de_micaelisto 14436 TRUE FALSE NA NA
## 5 isa_medina47 13222 TRUE FALSE NA NA
## 6 Lucas10805931 12765 TRUE FALSE NA NAAparecen figuras públicas como Nati Jota y Calu Rivero. También podemos ver algunas un poco más “anónimas”, como la usuaria malefilmica, que hizo un relato de ficción absolutamente estremecedor. Para trabajar con los wordclouds y el lexicón, necesitamos que esté todo en minúsculas, así que dejemos eso preparado para después.
mira_unique <- mira_unique %>%
arrange(desc(retweetCount)) %>%
mutate(text=tolower(text))
head(mira_unique)## text
## 1 rt @martucattoni: hoy me subí al colectivo, estaba sola. una parada despues se suben un par de personas. una de ellas, una señora de al red…
## 2 rt @soythelmafardin: #miracomonosponemos \nhttps://t.co/srosqj8dwk
## 3 rt @magalitajes: #miracomonosponemos\nla mierda de darthes no es un caso aislado, está avalado por un sistema que encubre, defiende y perpet…
## 4 rt @natijota: ni por borracha, ni por andar con poca ropa, ni por “buscona”, ni “por puta”. si no hay un explícito “sí”, es no. si es menor…
## 5 rt @riverocalu: #miracomonosponemos https://t.co/jtuibl5awy
## 6 rt @malefilmica: #miracomonosponemos\n\nhoy me levanté a las 10 como todas las mañanas, le mandé los buenos días a mi novio y me puse a ver v…
## favorited favoriteCount replyToSN created truncated
## 1 FALSE 0 <NA> 2018-12-19 18:25:18 FALSE
## 2 FALSE 0 <NA> 2018-12-19 16:00:05 FALSE
## 3 FALSE 0 <NA> 2018-12-19 15:42:37 FALSE
## 4 FALSE 0 <NA> 2018-12-19 20:05:00 FALSE
## 5 FALSE 0 <NA> 2018-12-19 17:06:41 FALSE
## 6 FALSE 0 <NA> 2018-12-19 20:34:14 FALSE
## replyToSID id replyToUID
## 1 <NA> 1075457058621788160 <NA>
## 2 <NA> 1075420512501841920 <NA>
## 3 <NA> 1075416117504548870 <NA>
## 4 <NA> 1075482150600892416 <NA>
## 5 <NA> 1075437276019286016 <NA>
## 6 <NA> 1075489507925995524 <NA>
## statusSource
## 1 <a href="http://twitter.com/download/iphone" rel="nofollow">Twitter for iPhone</a>
## 2 <a href="http://twitter.com" rel="nofollow">Twitter Web Client</a>
## 3 <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a>
## 4 <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a>
## 5 <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a>
## 6 <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a>
## screenName retweetCount isRetweet retweeted longitude latitude
## 1 lokapsi 22736 TRUE FALSE NA NA
## 2 mbinet_ 18983 TRUE FALSE NA NA
## 3 Byron_Rosales 18175 TRUE FALSE NA NA
## 4 de_micaelisto 14436 TRUE FALSE NA NA
## 5 isa_medina47 13222 TRUE FALSE NA NA
## 6 Lucas10805931 12765 TRUE FALSE NA NAVolviendo por un minuto a los usuarios más populares y los anónimos: ¿habrá algún tweet que haya generado mucho eco en el período analizado?
miracomonosponemos %>%
filter(isRetweet==FALSE) %>%
filter(retweeted==TRUE) %>%
arrange(desc(retweetCount)) %>%
select(screenName, text, retweetCount, favoriteCount) %>%
head()## [1] screenName text retweetCount favoriteCount
## <0 rows> (or 0-length row.names)Vemos que no: ningún tweet que no sea retweet fue a su vez retweeteado (parece un trabalenguas, ¿verdad?).
¿Y qué pasa con los favoritos? Vamos a ver aquellos que se generaron en este período que no sean retweets pero que hayan sido los más marcados como favoritos.
miracomonosponemos %>%
filter(isRetweet==FALSE) %>%
arrange(desc(favoriteCount)) %>%
select(screenName, text, retweetCount, favoriteCount) %>%
head()## screenName
## 1 AgustinLaje
## 2 actrices_arg
## 3 NanNFC2
## 4 exitoina
## 5 LaraMinervino
## 6 actrices_arg
## text
## 1 Sigo esperando sin éxito que @vikidonda salga a decir #MiraComoNosPonemos repudiando el texto en el cual su marido… https://t.co/Hus5RA4dH6
## 2 Un Estado que ante el aumento de llamados pidiendo ayuda despide, desfinancia y sobreexplota a sus trabajadorxs de… https://t.co/LdfTMcMniG
## 3 Thelma - Cuando tenía 16 años tuve sexo con Darthés <U+0001F61C>\nCalu - Me jodes!? <U+0001F632>\n-No, de verdad <U+0001F60D>\n-Pero eso es violación!<U+0001F631>… https://t.co/ZpMmS7bq26
## 4 #MiraComoNosPonemos Geraldine Neumann @gegeneumann y su marido acusaron a Ariel Rodríguez Palacios @ArielRoPalacios… https://t.co/6bTLahLpmC
## 5 #Miracomonosponemos https://t.co/avGu8yNmmP
## 6 Ésto dice nuestra compañera @zuleicaes sobre las amenazas que está recibiendo. La abrazamos, apoyamos y reafirmamos… https://t.co/tWyzFUDo5S
## retweetCount favoriteCount
## 1 1212 2348
## 2 129 270
## 3 59 172
## 4 67 79
## 5 97 72
## 6 21 59Aparecen Agustín Laje (un auténtico profeta del odio machista de la derecha joven), la cuenta de Actrices Argentinas y otros usuarios. Es interesante lo que se puede observar con los datos que brinda esta red social y un par de líneas de código.
Pero sigamos adelante: vamos a separar estos tweets en palabras y a fusionar esa base con el lexicón SDAL. En el medio, modificamos el lexicón para que “palabra” se llame “word”, así después podemos graficar con wordcloud. Una vez que tenemos eso, veamos qué sucede.
mira_word <- mira_unique %>%
mutate(text=str_remove_all(text, remove_reg)) %>%
unnest_tokens(Palabra, text) %>%
count(Palabra, sort=TRUE) %>%
filter(!Palabra%in%stopwords('es')) %>%
filter(!Palabra%in%fillers) %>%
filter(str_detect(Palabra, "^[a-zA-z]|^#|^@")) %>%
ungroup() %>%
arrange(desc(n)) %>%
mutate(word=Palabra,
freq=n) %>%
select(word, freq)
sdal_word <- sdal %>%
rename("word"=palabra)
mira_sdal <- left_join(mira_word, sdal_word, by="word")## Warning: Column `word` joining character vector and factor, coercing into
## character vectorhead(mira_sdal)## # A tibble: 6 x 9
## word freq media_agrado media_activacion media_imaginabi~ sd_agrado
## <chr> <int> <dbl> <dbl> <dbl> <dbl>
## 1 mira~ 494 NA NA NA NA
## 2 noes~ 62 NA NA NA NA
## 3 muje~ 51 NA NA NA NA
## 4 hoy 47 NA NA NA NA
## 5 metoo 46 NA NA NA NA
## 6 ahora 43 NA NA NA NA
## # ... with 3 more variables: sd_activacion <dbl>, sd_imaginabilidad <dbl>,
## # tipo <fct>Por lo pronto, vemos que el hashtag en cuestión es el término que más aparece, seguido de otros como noesno, metoo y niunamenos. Las columnas de agrado, activación e imaginabilidad están mejor descriptas en el trabajo, pero son bastante autoexplicativas: remiten a las sensaciones y emociones que esas palabras despiertan. Como mucho de lo que aparece son hashtags u otro tipo de construcciones, en esas columnas tenemos los tan temidos NA (pero que en este momento no nos preocupan).
Palabras necesarias
Vamos a ver entonces el wordcloud general, eliminando el primer término (que es el hashtag que estamos analizando).
hw <- wordcloud2(mira_sdal[2:500,], size = 0.5, gridSize = 8)
saveWidget(hw, "mira_wc.html", selfcontained = F)
webshot::webshot("mira_wc.html", "mira_wc.png", vwidth = 1024, vheight = 860, delay = 15)
Vemos que aparecen varios usuarios. Se destacan Thelma Fardín, Marcelo Tinelli (quien ahora en su programa está teniendo un vuelco feminista después de años de cortarle la pollera a las mujeres con una tijera) o la diputada Victoria Donda (cuyo marido, Pablo Marchetti, está siendo blanco de todo tipo de críticas por un relato ficcional de incesto y pedofilia que francamente revuelve el estómago). También aparece el hashtag pero escrito de otras formas: con o sin tildes. Otra peculiaridad del castellano que en este momento nos juega levemente en contra.
Acá viene lo interesante del lexicón SDAL: veamos qué sucede con aquellos términos que sí cuentan con un valor asignado en cuanto a su agrado. Las palabras en rojo son las que se consideran más negativas, y en verde las más positivas: el tamaño está dado por la cantidad de veces que aparece.
mira_sdal %>%
filter(!is.na(media_agrado)) %>%
ggplot(., aes(label=word, size=freq, color=media_agrado))+
geom_text_wordcloud_area(rm_outside = TRUE)+
scale_colour_gradient(low="#c90000", high="#009A44")+
scale_size_area(max_size=10)+
theme_minimal()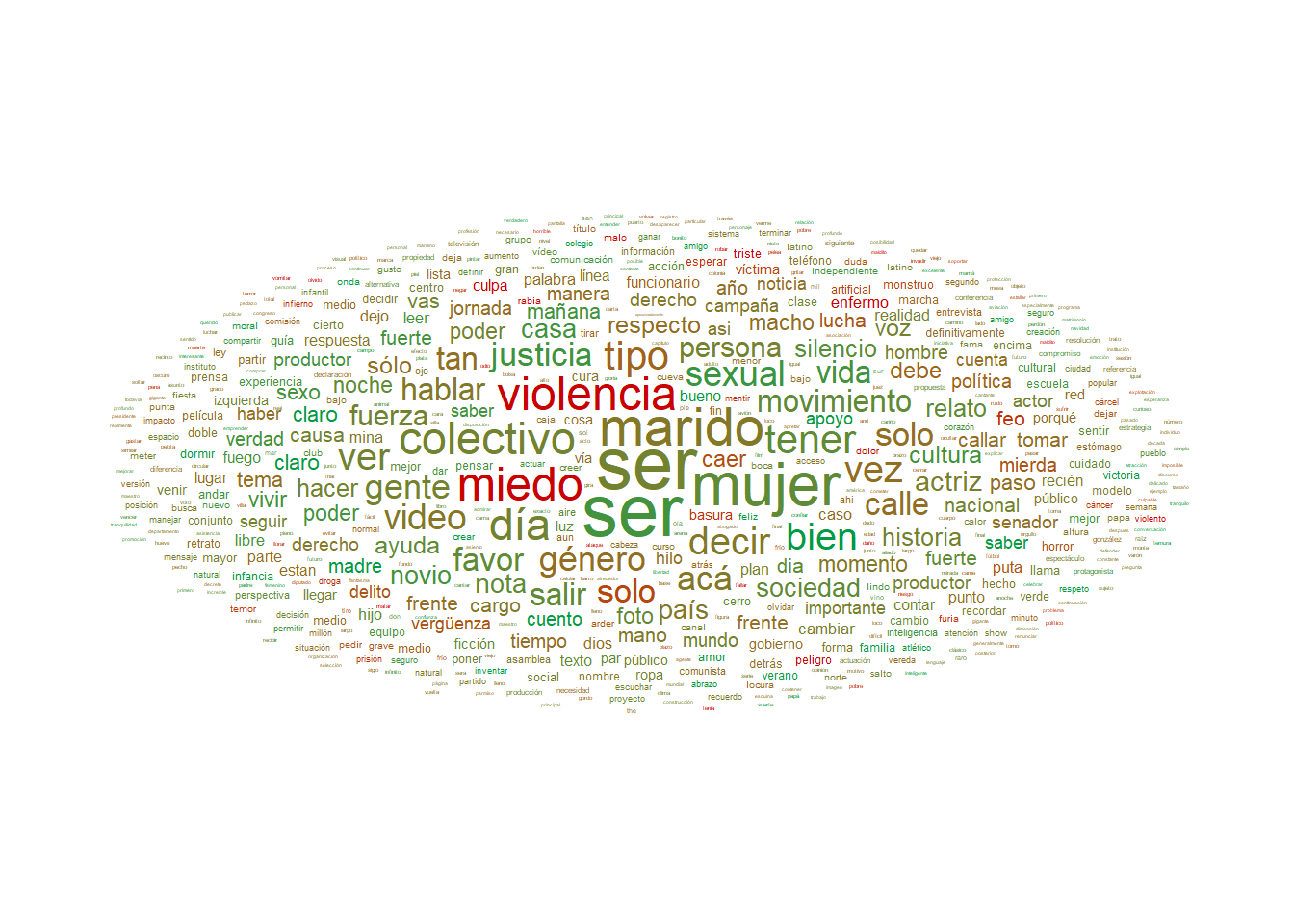
Es muy fuerte ver la presencia de la palabra miedo de una forma tan marcada. La otra palabra muy mencionada es mujer, que según la construcción de este lexicón, tiene una calificación eminentemente positiva. Se observan algunas repeticiones (como “ser”), por una sencilla razón: puede ser un sustantivo o un verbo, y ambas tienen puntajes diferentes. En parelelo, puntualmente por la forma de expresarnos que tenemos como argentinos, hacemos un alto uso de la ironía, lo que hace que muchas veces las palabras positivas aparezcan en un uso negativo. Es difícil calificar al idioma, pero ahí está su riqueza y belleza.
Para que haya una mayor claridad, hagamos unos gráficos de tipo lollipop para complementar la lectura. Primero, veamos cuáles son los 20 términos más mencionados, independientemente de su clasificación.
Vuelvo por un instante a lo técnico: hace su aparición la librería forcats, que lo que hace es forzar a la base a tomar un determinado orden. En este caso, lo que quiero hacer es que queden ordenadas por cantidad de menciones, dado que el default no es demasiado claro y queda desparejo.
mira_sdal %>%
arrange(desc(freq)) %>%
mutate(word=forcats::fct_inorder(word)) %>%
.[2:21,] %>%
ggplot(., aes(x=word, y=freq))+
geom_segment(aes(x=word, xend=word, y=0, yend=freq), color="grey")+
geom_point(size=3, color="#009A44")+
coord_flip()+
theme_economist()+
theme(
panel.grid.minor.y = element_blank(),
panel.grid.major.y = element_blank(),
legend.position="none") +
xlab("") +
ylab("Frecuencia")
Este gráfico es básicamente una reconstrucción del top de palabras, pero un poco más claro: aparecen los hashtags populares, así como también algunas palabras como “ahora”, “hoy” o “años”.
Por último, vamos a complementar el wordcloud por palabras calificadas según emociones con otros dos lollipops: ordenaremos la base por las medias de agrado y veremos cuántas veces aparecen las palabras más agradables y las más desagradables.
mira_sdal %>%
filter(!is.na(media_agrado)) %>%
arrange(desc(media_agrado)) %>%
.[1:20,] %>%
mutate(word=forcats::fct_inorder(word))%>%
ggplot(., aes(x=word, y=freq))+
geom_segment(aes(x=word, xend=word, y=0, yend=freq), color="grey")+
geom_point(size=3, color="#009A44")+
coord_flip()+
theme_economist()+
theme(
panel.grid.minor.y = element_blank(),
panel.grid.major.y = element_blank(),
legend.position="none") +
xlab("") +
ylab("Frecuencia")+
labs(title="Conteo de palabras: Positivas")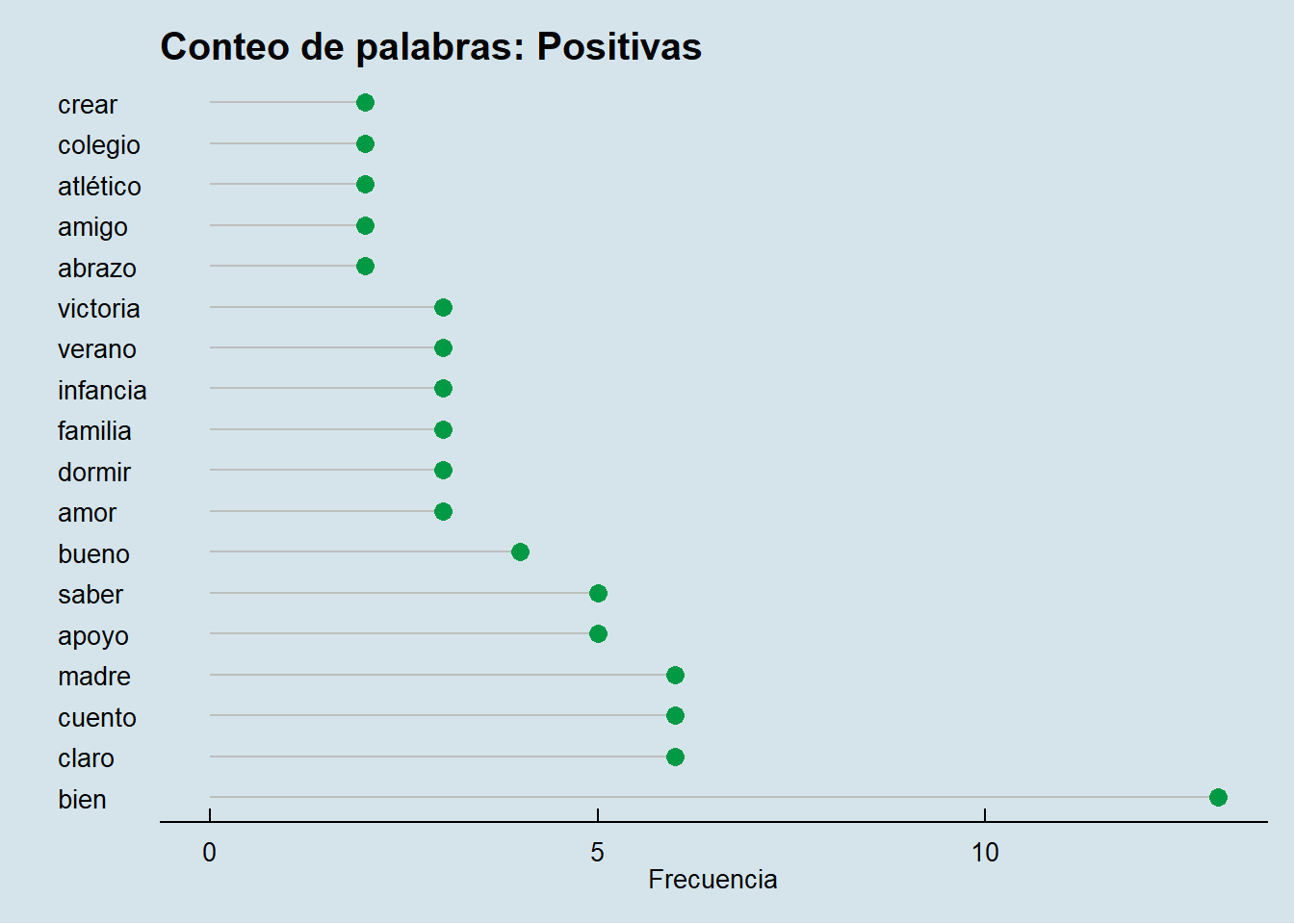
mira_sdal %>%
filter(!is.na(media_agrado)) %>%
arrange(media_agrado) %>%
.[1:20,] %>%
mutate(word=forcats::fct_inorder(word))%>%
ggplot(., aes(x=word, y=freq))+
geom_segment(aes(x=word, xend=word, y=0, yend=freq), color="grey")+
geom_point(size=3, color="#c90000")+
coord_flip()+
theme_economist()+
theme(
panel.grid.minor.y = element_blank(),
panel.grid.major.y = element_blank(),
legend.position="none") +
xlab("") +
ylab("Frecuencia")+
labs(title="Conteo de palabras: Negativas")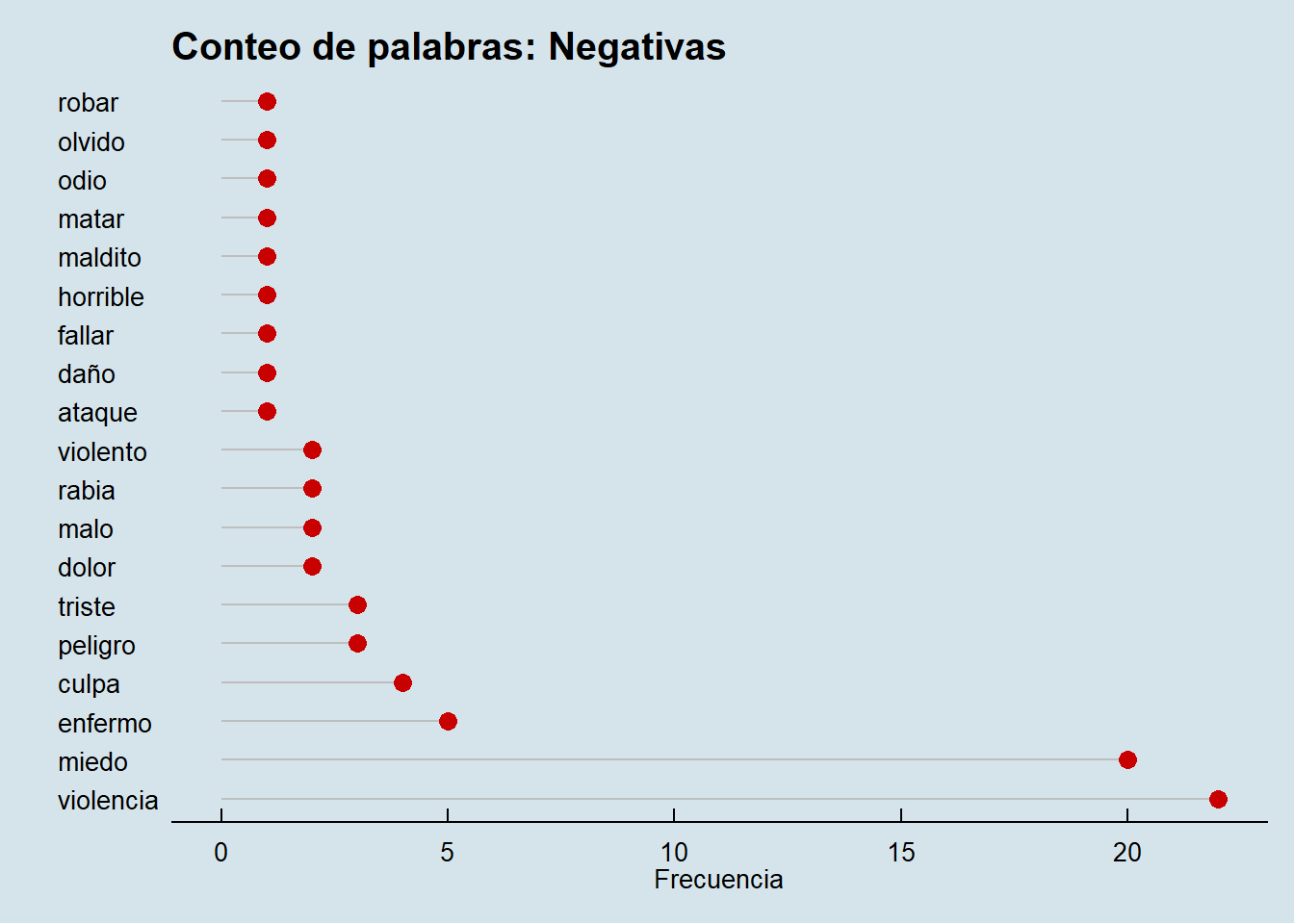
En cuanto a las positivas, aquí aparece de nuevo la cuestión de lo difícil de calificar del lenguaje: por ejemplo, en un contexto como este, me inclino a suponer que “colegio” no fue usada en una forma positiva. “Miedo” es una de las palabras con mayor peso en cuanto a su media de agrado, y apareció más de 20 veces, lo cual no es poco. En la comparación entre ambas, podemos encontrar que las palabras más desagradables aparecieron más veces que las palabras más agradables, lo cual es entendible.
Una oleada necesaria
A modo de cierre, no quería dejar de reiterar mi más sincero apoyo a todas las mujeres que se animan a denunciar situaciones de extrema vulnerabilidad que la violencia machista les ha hecho vivir. Aquí se ve muy claro el valor de este movimiento, que las hace sentirse acompañadas y valientes para sacar a la luz estos sucesos extremadamente oscuros. Es muy fuerte lo que se está viviendo como sociedad, y si bien es necesario que estos casos se den a conocer (y más aún es menester que este sistema patriarcal se caiga a pedazos), no deja de ser una sensación agridulce en tanto es la evidencia de una violencia que siempre existió pero no estaba problematizada.
El patriarcado se va a caer, porque las mujeres que luchan lo van a tirar abajo. Ojalá ese día sea pronto.
