
La línea de pobreza en el segundo trimestre: analizando la EPH
Hace unas semanas tuve la suerte de poder asistir a un curso organizado por INDEC-CEPED, brindado por auténticos referentes en all things R: Natsumi Shokida, Diego Kozlowski y Guido Weksler. Ahí se trabjó la aplicación de R para el análisis de la Encuesta Permanente de Hogares (EPH), una de las herramientas más valiosas que tiene el Instituto.
Esta herramienta releva información de 31 aglomerados del país de manera trimestral y es fundamental para observar cómo evolucionan indicadores de pobreza, trabajo y hábitat de una manera mucho más periódica que el censo.
Data wrangling
Se sabe que el ordenamiento de las bases de datos insume la mayor cantidad de tiempo en lo que hace al análisis de datos. En este caso pude comprobarlo de primera mano, porque reacomodar la información para que quede en formato tidy lleva sus líneas de código. Pero vamos por partes.
Primero, a levantar la base de la EPH y los mapas de Argentina y los departamentos. Cabe mencionar que tuve que hacer un importante corte en el mapa del territorio nacional respecto a la versión que encontré en el portal de Datos Abiertos Nacionales porque si lo dejaba en su versión original, la Antártida ocupaba casi la mitad del espacio, así que sacrifiqué un poco de precisión geográfica en aras de una mejor visibilidad.
Quien quiera los archivos que preparé en los que armé ese recorte del territorio argentino y aislé los puntos que releva la EPH, se lo mando sin ningún problema.
library(sf)## Linking to GEOS 3.6.1, GDAL 2.2.3, proj.4 4.9.3library(tidyverse)## -- Attaching packages ------------------------------------------------- tidyverse 1.2.1 --## v ggplot2 3.0.0 v purrr 0.2.5
## v tibble 1.4.2 v dplyr 0.7.6
## v tidyr 0.8.1 v stringr 1.3.1
## v readr 1.1.1 v forcats 0.3.0## -- Conflicts ---------------------------------------------------- tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(openxlsx)
t218 <- read.table("../../../datasets/eph/usu_individual_t218.txt", sep = ";", dec=",", header=TRUE, fill = TRUE)
argentina <- read_sf('../../../datasets/eph/EPH/mapaARG.geojson')
agloEPH <- read_sf('../../../datasets/eph/EPH/mapaEPH2.geojson')Ahora que tenemos esto, lo que sigue es construir el indicador de la línea de pobreza. Estos insumos los brindaron los docentes del taller y están disponibles de manera abierta. En cuentas resumidas son tablas para saber las unidades de adultos equivalentes, las canastas básicas alimentarias y totales y un diccionario de regiones para traducir la codificación de la base. También hago una selección de las variables que me interesan de la base total, porque trabajar sobre las más de 170 variables de la EPH consume demasiada memoria si no las vamos a usar.
Adequi <- read.xlsx("../../../datasets/eph/ADEQUI.xlsx")
CBA <- read.xlsx("../../../datasets/eph/CANASTAS.xlsx", sheet = "CBA")
CBT <- read.xlsx("../../../datasets/eph/CANASTAS.xlsx", sheet = "CBT")
aglomerados <- read.xlsx("../../../datasets/eph/codigo_aglo.xlsx")
dic.regiones <- read.xlsx("../../../Curso R-CEPED-INDEC/Fuentes/Regiones.xlsx")
var.ind <- c('CODUSU','NRO_HOGAR' ,'COMPONENTE','ANO4','TRIMESTRE','REGION',
'AGLOMERADO', 'PONDERA', 'CH04', 'CH06', 'ITF', 'PONDIH','P21')Ahora toca acomodar las canastas: primero cambiarles el nombre para poder unirlas y luego ordenarlas según los principios tidy: una fila por observación, una columna por variable. Además, hay que agregar los datos de período para poder unir con posteriores tablas.
CBA <- CBA %>%
mutate(Canasta = "CBA")
CBT <- CBT %>%
mutate(Canasta="CBT")
Canastas <- bind_rows(CBA, CBT)
canastas2 <- Canastas %>%
gather(Region, Valor, c(3:8)) %>%
mutate(Trimestre=case_when(Mes%in%c(1, 2, 3)~ 1,
Mes%in%c(4, 5, 6)~ 2,
Mes%in%c(7,8,9)~3,
Mes%in%c(10,11,12)~4),
Periodo=paste(Año, Trimestre, sep="."))
canastas3 <- canastas2 %>%
group_by(Canasta, Region, Periodo) %>%
summarise(Valor=mean(Valor)) %>%
spread(.,Canasta, Valor) %>%
left_join(., dic.regiones, by="Region") %>%
ungroup()Ahora llega el momento de juntar toda esta información: filtramos la base total seleccionando sólo las variables que interesan y se combina la información.
eph_filtrada <- t218 %>%
select(var.ind)
eph_canastas <- eph_filtrada %>%
mutate(Periodo=paste(ANO4, TRIMESTRE, sep=".")) %>%
left_join(., Adequi, by=c("CH04", "CH06")) %>%
left_join(., canastas3, by=c("REGION", "Periodo"))Para construir la tasa, se agrupa para conseguir la cantidad de adultos equivalentes por observación y se clasifica los hogares según su situación.
eph_canastas2 <- eph_canastas %>%
group_by(CODUSU, NRO_HOGAR, Periodo) %>%
mutate(Adequi_hogar=sum(adequi)) %>%
ungroup() %>%
mutate(CBA=CBA*Adequi_hogar,
CBT=CBT*Adequi_hogar,
Situacion=case_when(ITF<CBA~ "Indigente",
ITF>=CBA & ITF<CBT~ "Pobre",
ITF>=CBT~ "No.Pobre"))Para construir las tasas de pobreza e indigencia por aglomerado, ahora hay que hacer la media de hogares en cada situación promediados por su lugar.
eph_tasacanasta <- eph_canastas2 %>%
group_by(AGLOMERADO) %>%
summarise(Tasa_Pobreza=sum(PONDIH[Situacion %in% c('Pobre', 'Indigente')],na.rm = TRUE)/
sum(PONDIH,na.rm = TRUE),
Tasa_indigencia = sum(PONDIH[Situacion == 'Indigente'],na.rm = TRUE)/
sum(PONDIH,na.rm = TRUE),
Tasa_total=sum(Tasa_Pobreza, Tasa_indigencia))
eph_tasa_mapa <- left_join(eph_tasacanasta, aglomerados, by="AGLOMERADO")
eph_tasa_provincia <- eph_tasa_mapa %>%
group_by(Provincia) %>%
summarise(Linea=mean(Tasa_total))La idea en el gráfico era la de calcular el tamaño de los puntos en función del aglomerado, con lo que necesitamos pasarle esos datos al .geojson que tiene los 31 puntos.
mapa_eph_final <- left_join(eph_tasa_mapa, agloEPH, by="AGLOMERADO")¡Costó pero llegamos! Ahora sí está listo el archivo que combina todo lo necesario. Ahora es cuestión de armar el ggplot apilando dos capas: la del territorio nacional y la de los 31 puntos de la EPH con sus resultados.
ggplot()+
geom_sf(data=argentina)+
geom_sf(data=mapa_eph_final, aes(color=Tasa_total*100), size=2)+
scale_color_continuous(low = "#34a853", high = "#ea4335", name="Porcentaje",
breaks=c(20, 30, 40, 50),
labels=c("20%", "30%", "40%", "50%"))+
labs(title="Cantidad de individuos bajo la línea de pobreza en los aglomerados de la EPH",
subtitle="Segundo trimestre del 2018",
caption="Fuente: EPH, INDEC, indec.gob.ar")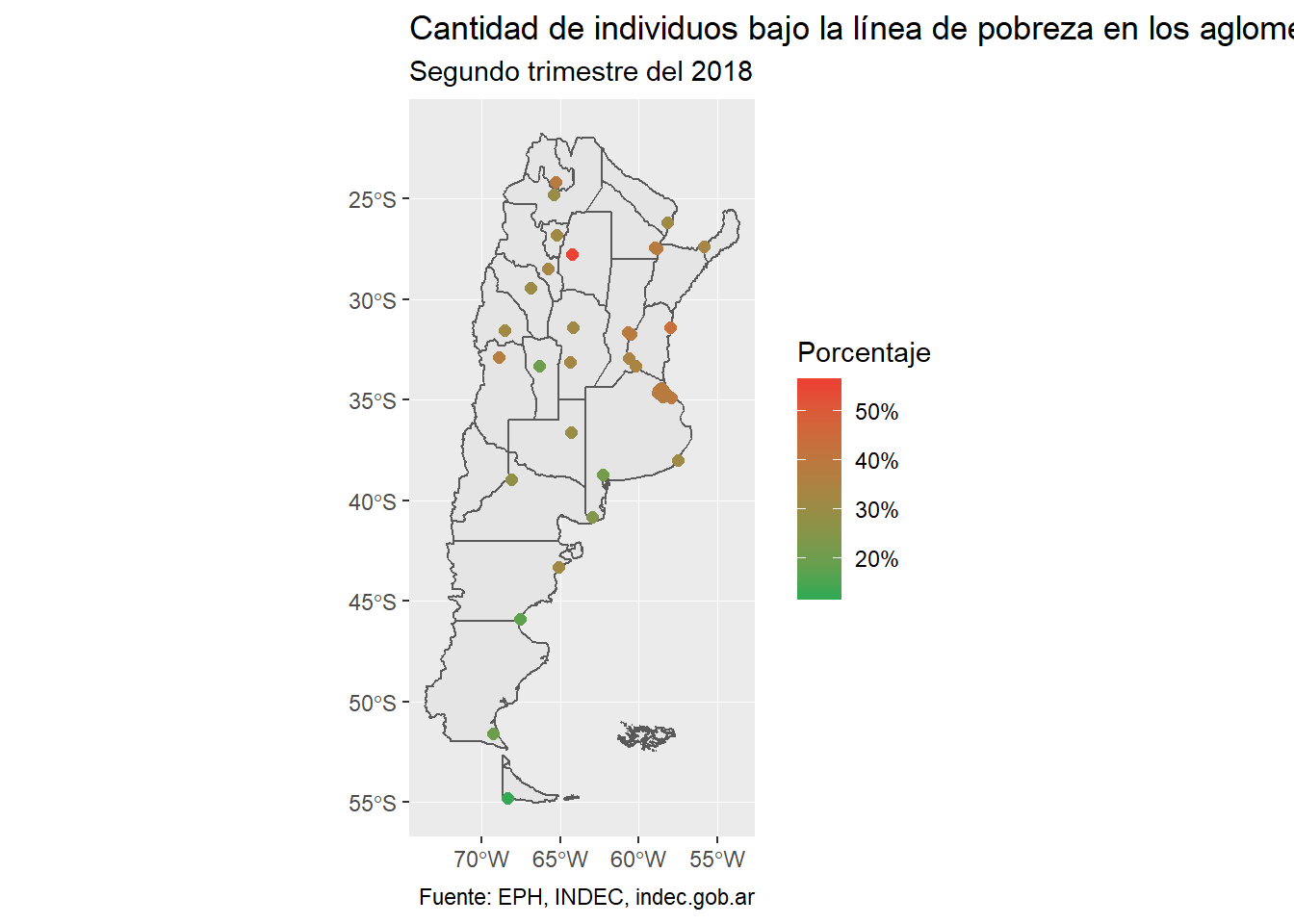
Conclusión
Lo que se observa en el gráfico es fuerte: de acuerdo a los datos relevados, la cantidad de personas bajo la línea de la pobreza es considerable, situación que reviste particular gravedad en el NOA, el NEA y tiene su punto máximo en Santiago del Estero, donde este porcentaje llega al 55,5%.
Es importante hacer una aclaración metodológica. La EPH se releva en 31 aglomerados urbanos, lo que significa que este gráfico no representa ámbitos rurales o ciudades y pueblos de una menor densidad poblacional. En este contexto, no es imposible suponer que el panorama es aún más alarmante que el que se ve en este gráfico.
Sería un interesante trabajo intentar tomar los elementos de la Canasta Básica Alimentaria (CBA) y analizar muy profundamente lo que contiene. Si algún experto en salud lee esta publicación, me interesaría saber su opinión sobre lo que se sugiere como mínimo sustento nutricional de una persona; a priori imagino que debe haber mucho que puede hacerse para mejorar la calidad alimenticia en líneas generales.
